Do ponto de vista de desenvolvimento de APIs e softwares, usar uma string que não seja para filtrar nomes, acho isso bem frágil.
Não sei porque você tem essa impressão mas não há razão para se falar em fragilidade, é só impressão. Em especial quando se trata de OSM. Um arquivo OSM é na verdade um arquivo XML onde só existe string. Tudo lá é string desde a representação dos elementos básicos (nós, caminhos e relações) até os pares chave, valor (até mesmo os dados com interpretação natural numérica - coordenadas, velocidade, peso, data e hora, etc) nos metadados (atributos) e nos dados (tags e valores). Assim, o parsing de um arquivo .osm é fundamentalmente um processamento de strings com comparações e filtragens baseadas tanto nas chaves como nos valores. Ou seja, todo o OSM depende fundamentalmente de strings.
Não estou dizendo isso apenas teoricamente, lido com parsing de OSM (XML) há anos, seja com parser de terceiros ou com o meu próprio. O parsing do XML e a estruturação dos dados são básicos para geração de mapas, para extração de alertas, para verificação de qualidade (relações quebradas, ausência de dados, dados incoerentes) e correção/atualização (edição automática do XML) como nos casos recentes que fiz de limites estaduais e municipais, atualização de dados populacionais, reclassificação dos places e atualização/inclusão dos IBGE:GEOCODIGO. Tudo é feito basicamente com comparação e filtragem baseada em strings.
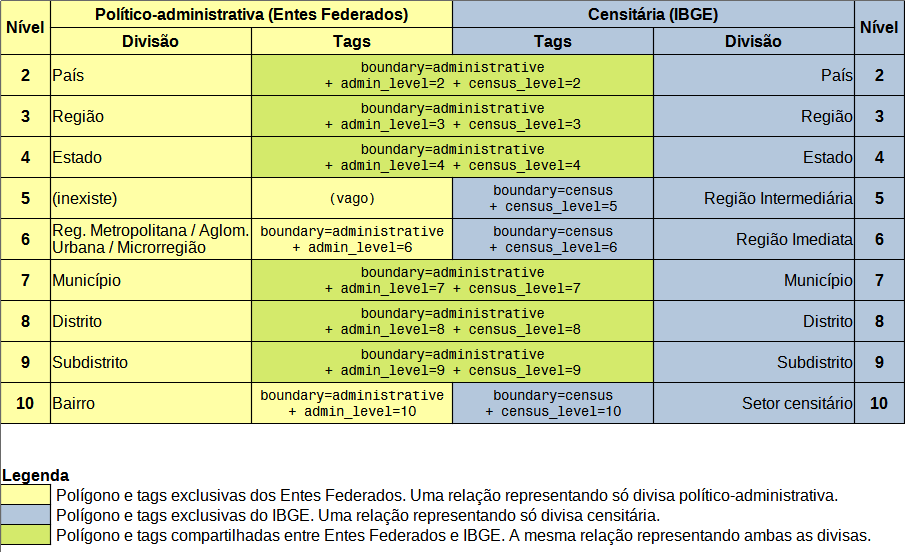
Já census ~Região Geográfica Imediata força a filtragem pelo nome e se utiliza de uma redundância (pode haver erro de digitação)
Erro de digitação sempre pode haver, mas em um nome é mais fácil de ser percebido e corrigido por qualquer pessoa do que em um número.
ou então para evitar redundância, seria preferível:
boundary=census
IBGE:census=Região Geográfica Imediata
name=Sorocaba
Sim, poderia ser assim. Quando usei o próprio valor “IBGE:CENSUS” como uma tag de hierarquia inferior cujo valor seria o nome da região, a ideia foi eliminar uma tag, essa do nome em seguida que você sugeriu. A ideia é semelhante ao nome de uma rua, onde colocamos o tipo da via (Rua, Avenida, Travessa, etc) no próprio nome e não numa tag adicional, o que também seria uma solução embora mais espaçosa. Nota: se você precisar importar dados do OSM para um banco de dados, para processamentos bem mais pesados, pode ser interessante quebrar em 2 campos, tipo da via + nome, mas de modo geral isso não é necessário.
No caso de vias, a filtragem pelo tipo já é feita assim, pelo nome. Ex. se quisermos filtrar todas as “Travessas” temos de filtrar pelo nome, mais especificamente pela parte inicial do nome.