Så, har nog kommit till punkten där jag måste sluta göra “bara en grej till” och faktiskt få ut det för att få in lite kommentarer (och förhoppningsvis användning!).
Jag har i några månader nu pysslat med ett system för att:
- Hämta öppna data från diverse källor
- Jämföra med OSM
- Ta fram avvikelser som kan behöva åtgärdas i OSM
- Presentera avvikelserna på ett sett som gör det möjligt att titta på dem och vid behov åtgärda i OSM
Vill man inte läsa mer kan man besöka webbappen direkt här: osm-bjk.jandal.se (BJK står för BästaJävlaKartan, för det är vad OSM borde bli ![]() )
)
Det tekniska för den som är intresserad
Systemet är uppdelat i tre delar
Databas
En PostgreSQL+PostGIS-databas som lagrar aktuellt OSM-data, hämtat data från olika källor samt avvikelserna, plus lite metadata för att kunna presentera det hela snyggt och sorterat för användaren.
Framför databasen sitter ett API (i form av PostgREST, som tar databasen som den är och automatiskt ger ett REST API), samt även en vectortiletjänst (pg_tileserv).
Processhantering
Airflow (ett system som hanterar olika körningar/processer) tillsammans med olika processer, skrivna i Python.
Varje process har ett syfte, t.ex. hämta en viss datamängd eller beräkna avvikelser enligt en viss algoritm.
Webbsida
En webbapp skriven i TypeScript & React, med Mantine som UI-ramverk, OpenLayers för kartor, m.m.
Infrastruktur
Koden finns på Github, men p.g.a. datamängderna rekommenderar jag ingen att försöka sätta upp det hela själv. Vill man bidra så går det dock lätt att jobba på frontend, och nya hämtningsrutiner eller avvikelse-algoritmer kan jag bistå med mindre uttag av datat så att det blir hanterligt.
Allt körs på en server i Kubernetes (mest för att jag ville lära mig det) bakom Cloudflare.
Beräkning av avvikelser
Hela projektet är ganska SQL-tungt; och för stunden beräknas alla avvikelser genom databasvyer. Det har sina fördelar, men kommer nog inte försöka implementera alla avvikelser i SQL, utan kan även komma att bli några i Python.
Gränssnittet
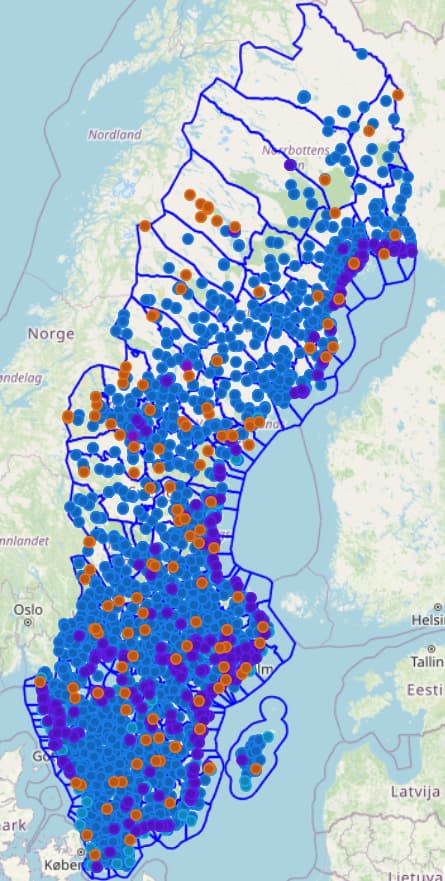
När man först kommer in på sidan möts man av en karta över alla avvikelser som systemet hittat (24 300 i skrivande stund). Här kan man även filtrera avvikelserna utifrån datakälla, kommun, företeelsetyp (t.ex. byggnad, badplats, m.m.) och typ, samt ladda ner filtreringsresultatet som osmChange-fil eller öppna det direkt i JOSM (funkar inte riktigt än).
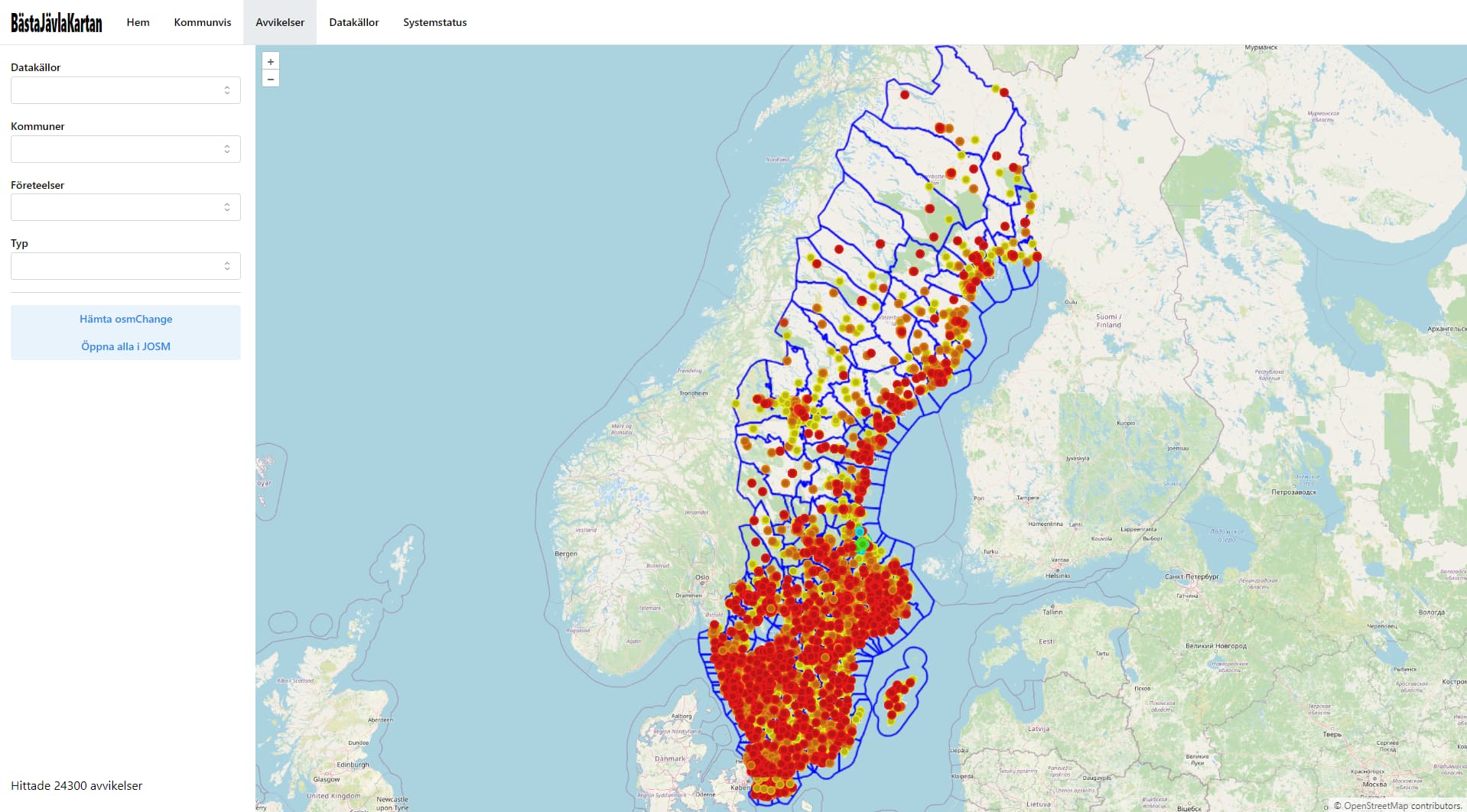
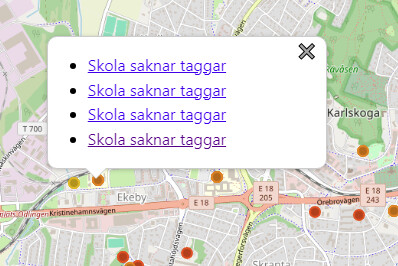
Klickar man på en avvikelse kommer man till dess sida, där man får mer information; vad är det som avviker, vilka taggar föreslås att läggas till/ändras, vart kommer datat som använts för att beräkna avvikelsen ifrån, etc. Även andra närliggande avvikelser visas här (som rosa kryss i kartan samt i listan till vänster) för att lättare kunna avgöra om det kanske blivit något fel där många avvikelser ligger nära varandra. Här finns länkar för att öppna avvikelsen i iD eller JOSM (för det senare följer även de föreslagna taggarna med direkt).
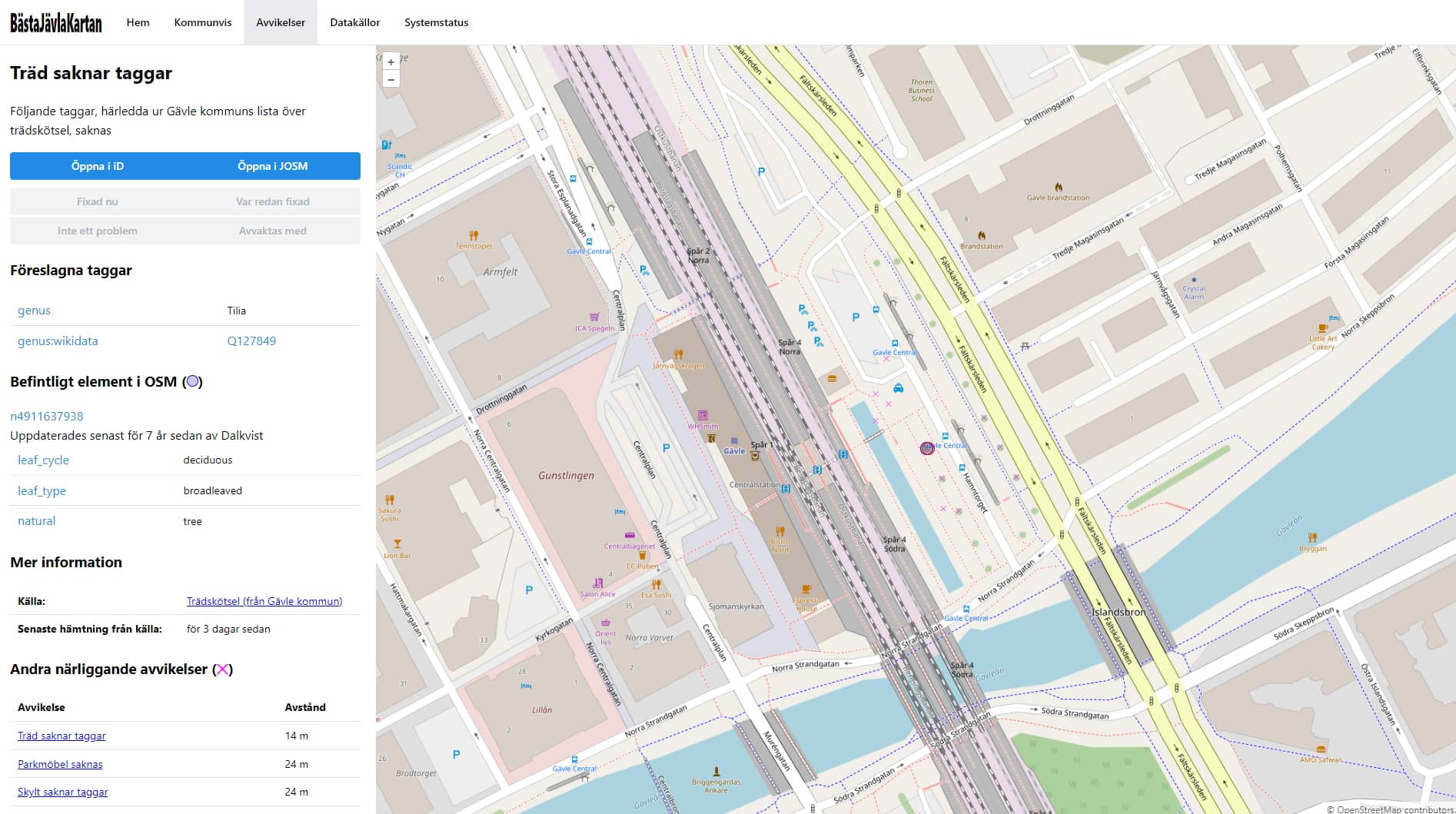
Vill man få en översikt över alla kommuner kan man gå in på Kommunvis / Tabell, där man får upp en tabell över alla kommuner och företeelsetyperna och kan se vart det finns många avvikelser. Här visas även bl.a. när en viss företeelsetyp senast kontrollerats av någon (just nu är det bara innehållet från wikin för NVDB-importen, men jag har planer för att utveckla det mer i framtiden).
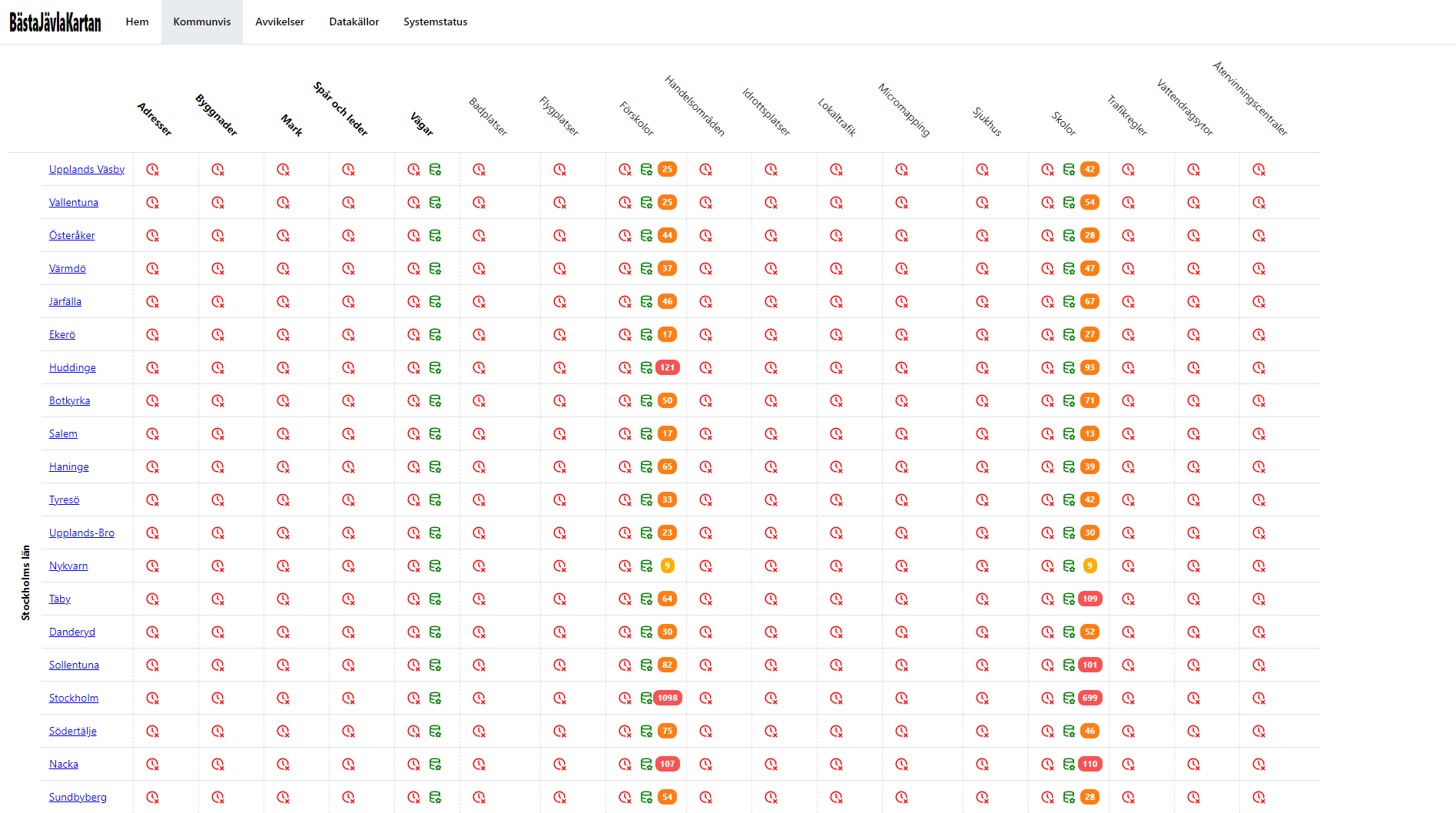
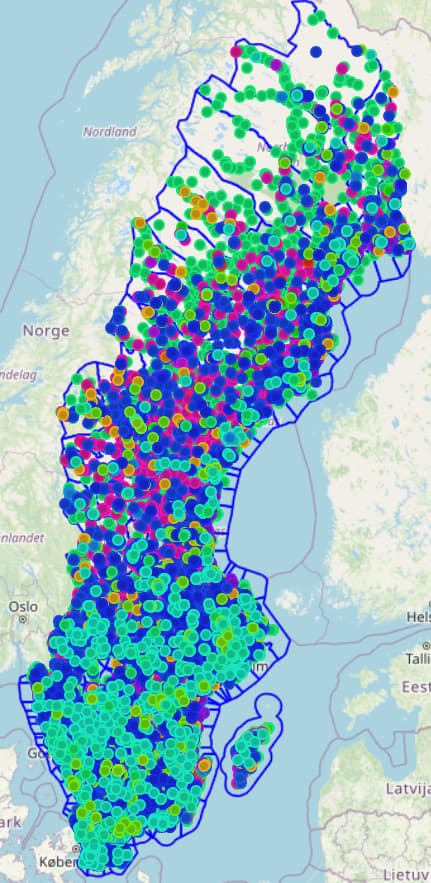
Gillar man kartor (dum fråga) så kan man gå in på Kommunvis / Karta, och får då samma information fast på en karta istället (och kan då välja lite olika sätt att visualisera på).
En lista över alla datakällor som hämtats finns under Datakällor, inga jättespännade saker här men kan vara intressant att se lite vad som hämtats redan. Notera dock att det är långt mer data som hämtats än vad jag hunnit skriva algoritmer för att beräkna avvikelser för.
Sist så finns en sida för att visa status över de olika processerna, Systemstatus. Utöver att se när de senast körts kan man här även manuellt trigga dem; användbart t.ex. om man precis gått igenom och åtgärdat en massa och vill få det uppdaterat i systemet. För att köra en process klickar man på dess ikon.
Aktuell status
Utöver den grundläggande funktionaliteten så finns just nu:
- Hämtning från Gävle kommun, SCB (Förskolor och Myndighetskontor) och Skolverket (Skolenhetsregistret)
- Avvikelser för 12 datamängder
Framtidsplaner/Roadmap
Integration med MapRoulette. Initiallt var tanken att ha något liknande (men enklare), finns lite spår av det kvar, men kom till slut fram till att det blir bättre att integrera med ett etablerat verktyg. Stötte dock på lite problem där och väntar på svar från utvecklaren, han skulle återkomma till veckan.
Fler datamängder. Säger sig självt, finns fortfarande en hel del kvar. För många (speciellt många intressanta) behövs dock även lite “mjukt” arbete, d.v.s. kontakt med myndigheten för att t.ex. få tillåtelse att använda CC-BY data. Här får man jättegärna hjälpa till!
Fler avvikelser. Säger sig också självt. Speciellt intressant blir det att börja beräkna avvikelser för annat än punktobjekt (som såklart är enklast).
Bättre infrastruktur. Just nu körs det på en server jag har stående i en lokal, det är en ganska gammal burk (enbart HDD, inga SSD) och den kör även diverse andra grejer. Skulle gärna flytta allt till en bättre server (men det kostar såklart). Även lite grejer som backup m.m. saknas.
Småfix, t.ex. anpassning till mindre skärmar (mobiler), bättre dokumentation, flerspråkigt gränssnitt, m.m.
Nästan viktigast, men det hela skulle behöva dokumenteras på wikin. Jag tror inte det faller under importreglerna till 100% (eftersom systemet är ganska tydligt med att det bara är indikationer, man ska fortfarande titta på varje objekt för sig manuellt), men för att allt ska vara helt grönt vore det nog bra att ändå dokumentera det enligt importreglerna så att ingen blir sur.
Sen har jag även lite långsiktiga planer. Som jag nämnde ovan finns det stöd i gränssnittet för att visa när en viss företeelsetyp senast kontrollerats av någon, detta skulle jag gärna bygga vidare på då jag tror det finns potential för ett sådant verktyg i OSM, där man när man t.ex. gått igenom lokaltrafiken i ett område kan “klarmarkera” det, så att nästa ser hur länge sedan det gjordes och därmed kan fokusera energin på det som ger mest värde. Men det är ännu bara grova idéer, vi får se vart de landar till slut…
Sist så tror jag även att detta kan vara en bra bas för att i framtiden göra visa automatiska ändringar i OSM, t.ex. om det tillkommer en byggnad eller något. Men det är nog väldigt långt borta.
Hjälpa till?
Först om främst skulle jag bli jätteglad om andra vill testa det hela lite! Lek runt, se vad ni tycker. Är det användbart? Ger det ett värde? Något man borde ändra på? Något som inte fungerar? Fritt fram att kommentera med alla tankar och idéer här!
Vill man ge sig in djupare finns det mycket att hjälpa till med såklart:
- Kontakta organisationer som har intressant data som inte är öppet eller öppet med fel licens för att få godkännande att använda datat
- Utveckla webbappen
- Skriva nya hämtningsrutiner (kräver att man sätter upp en Airflow-installation så lite meck med det, men i övrigt hanterligt)
- Skriva nya avvikelse-algoritmer (kräver data att utveckla mot, säg till för vilken datamängd och vilket område då vill jobba med så fixar jag ett uttag som inte kräver hela databasen)