HIFLD General Manufacturing (Florida)
Hello, I am proposing to import the General Manufacturing Facilities dataset, sourced from HIFLD, in the state of Florida.
Documentation
This is the wiki page for my import:
https://wiki.openstreetmap.org/wiki/HIFLD/Commercial
This is the source dataset’s website:
The data download is available here:
This is a file I have prepared which shows the data after it was translated to OSM schema:
https://cloud.disroot.org/s/tEeaZwF9seB4Y44/download/generalmanufacturing-florida.geojson
License
I have checked that this data is compatible with the ODbL.
This data is distributed under public domain.
Abstract
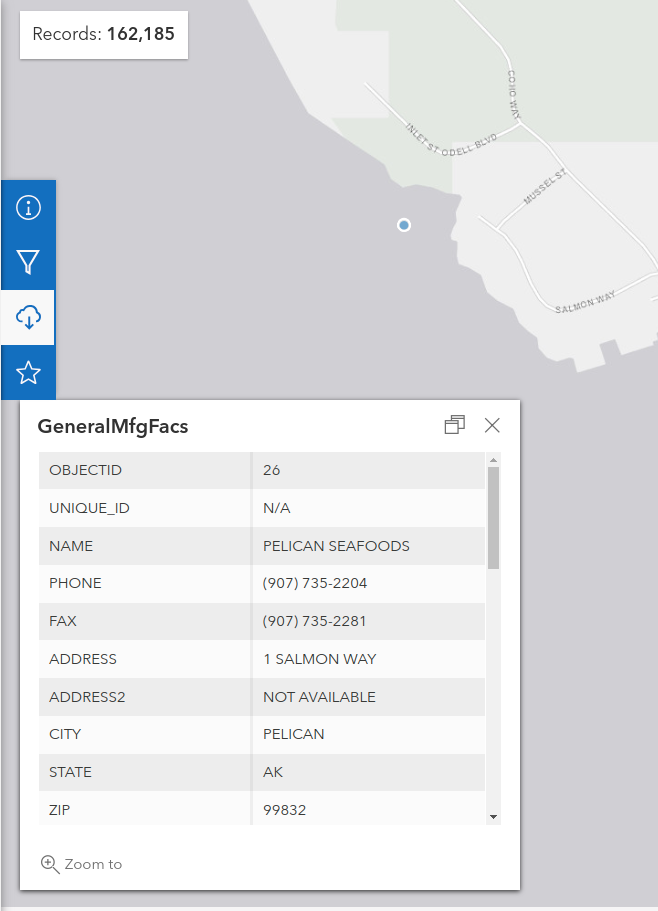
The General Manufacturing Facilities dataset provides data about factories and headquarters in the US. The dataset has 162,185 objects last I checked, but the current plan is to start by adding the data only in Florida, which totals 5,905 objects. I want to set up a maproulette task where users can review individual objects, and add to OSM after cleaning any issues.
The tag translations as listed on the wiki:
| HIFLD Tag | OSM Tag |
|---|---|
| man_made=works | |
| NAME | name |
| PHONE | phone |
| ADDRESS | addr:* |
| CITY | addr:city |
| STATE | addr:state |
| ZIP | addr:postcode |
| PRODUCT | product |
| WEB | website |
| DIRECTIONS | note |
The Changeset tags as listed on the wiki:
| Key | Value |
|---|---|
| comment | Importing Facility from HIFLD General Manufacturing Facilities |
| import | yes |
| source | HIFLD |
| source:url | General Manufacturing Facilities |
| source:date | 2021-03-15 |
| import:page | HIFLD/Commercial - OpenStreetMap Wiki |
| source:license | PD |
No conflation process has been done on the dataset, contributors will be expected to review if the object already exists, and add metadata or not import the object if already present.
These are the instructions I plan on giving on the MR project:
1: Visit the website, if one is provided, or sleuth using the internet to verify if the company is still operating
1: Verify address is correct, and the street is correctly formatted to match the name of the street on OSM.
3: Verify the object is in the correct location on the correct facility
4: Verify if the object is a factory or other type of facility, and change tags appropriately.Don’t try to guess where a facility is located. If it’s not possible to figure it out, mark the task as too hard.
Please take a look at the GeoJSON provided and share your thoughts.
Thanks,
–James Crawford