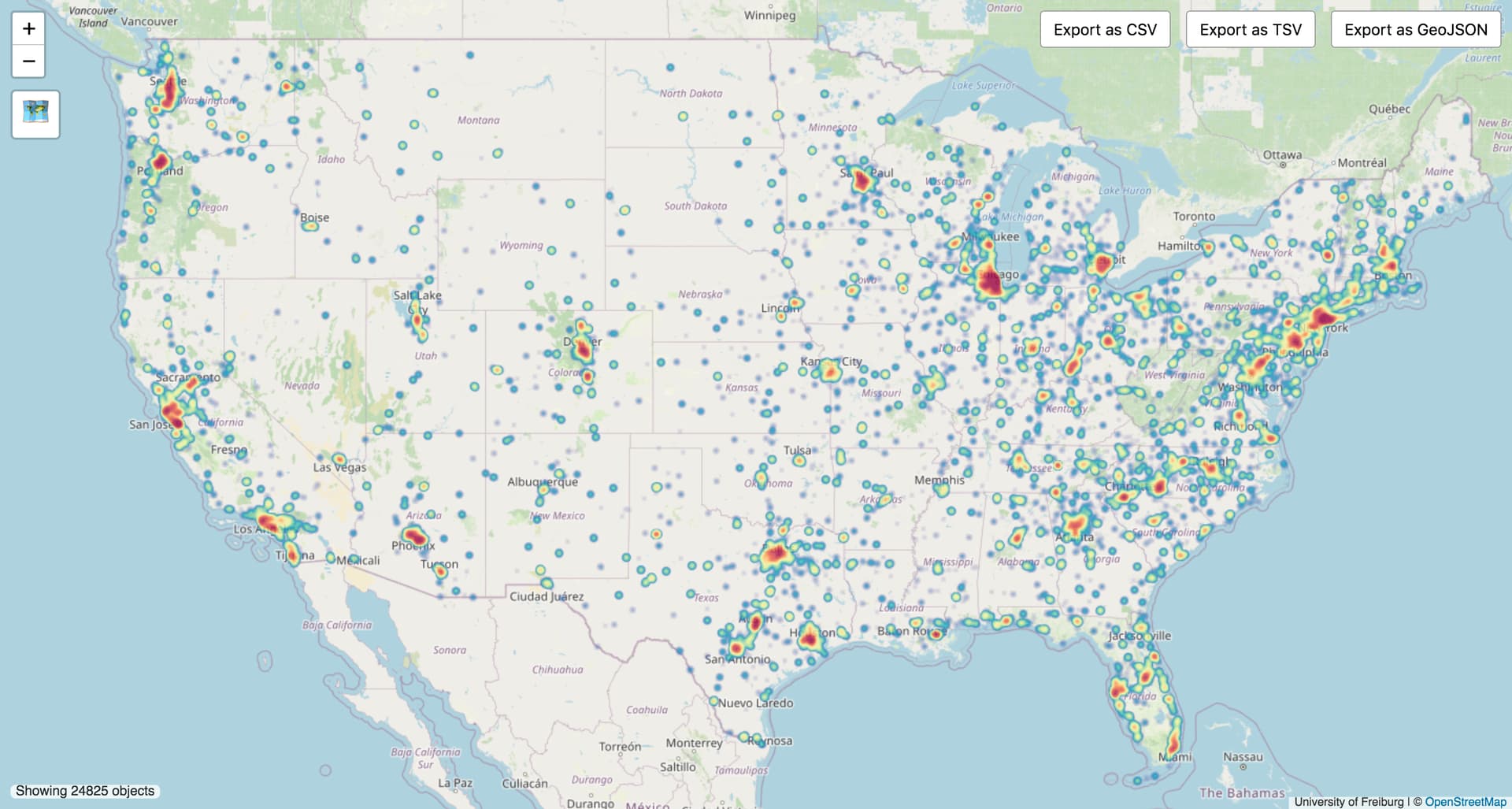
I am proposing a bulk removal of the brand:wikipedia tag from United States POIs.
Problem Statement
brand:wikipediais no longer automatically maintained by iD and thus is likely to become out of date over time. In the words of @Minh_Nguyen:
“if there’s any mismatch between the
brand:wikipediaandbrand:wikidatatags,brand:wikipediais almost guaranteed to be wrong.”
-
brand:wikipediaprovides no additional data not already provided for inbrandandbrand:wikidata, which are maintained in Name Suggestion Index and updated automatically by iD. As iD updates the other two brand tags,brand:wikipediaremains untouched. Thebrandtag provides a human-readable brand name, so there is no need to keepbrand:wikipediaaround merely for human readability. -
The existence of this tag on current objects creates an implied need for mappers to maintain them, when such maintenance is useless work when it can just be removed and mappers can focus on more important work.
-
Removing this tag removes the risk that an unaware data consumer will consume the
brand:wikipediatag and ingest wrong information from OSM.
Background
When tagging a brand (let’s use the most American example, McDonald’s), iD allows you to select a preset for that brand in the “Feature Type” pull-down:
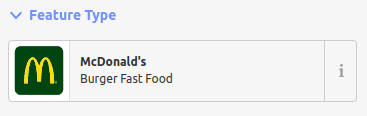
Selecting “McDonald’s” automatically populates six tags on that POI, as follows:
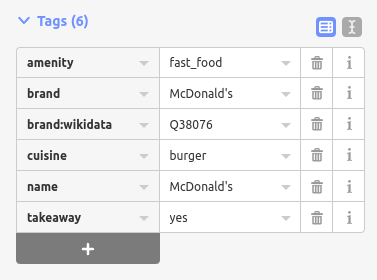
Thus, brand information is expressed in two tags:
- The
brandtag, which is a human-readable text string containing the brand - The
brand:wikidatatag, which points to the wikidata item for McDonald’s.
With this tagging, data consumers have a choice in consuming brand information: take the brand text string from the brand tag, or query the wikidata item, from which they can follow links to various language wikipedias, download a logo icon, or obtain other linked information about the POI not normally kept in OSM.
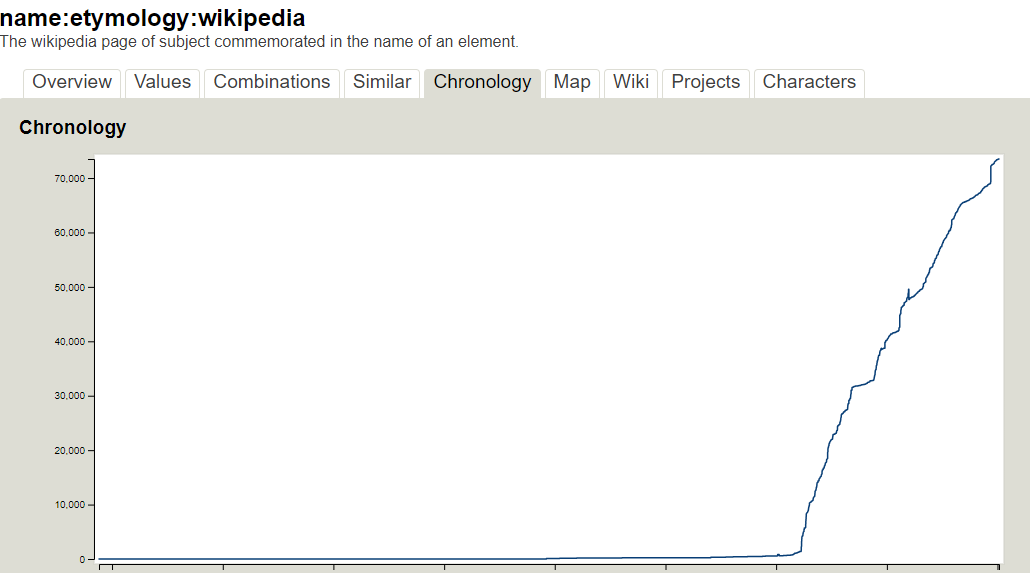
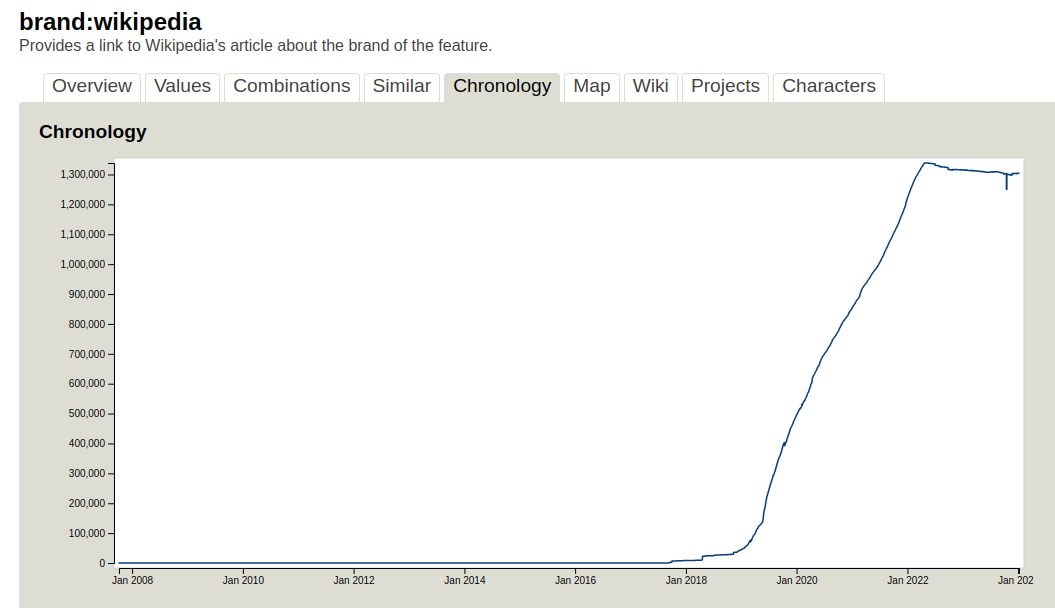
From about a 3-year period from 2018-2021, an additional tag, brand:wikipedia was also automatically added by iD via the Name Suggestion Index to POIs added by mappers, after which this behavior was discontinued. During this timeframe, 1.3 million brand:wikipedia objects were added globally. Since this behavior was removed, brand:wikipedia has been on a slow decline, as shown in this taginfo chronology:
Proposed Action
Via a series of geographically compact mechanical edits (for example, California alone has 22,000 cases of brand:wikipedia and would take a minimum of three changesets), remove the brand:wikipedia tag on all objects where a brand:wikidata and brand tag are already present.