It’s too late… OSMUS Slack has already hung a whole #place-classification channel off this thread, with an eye toward writing new national guidelines along the lines of the 2021 highway classification overhaul. The “inflation” that prompted this thread has already been reverted anyhow.
There’s no easy answer. A couple years ago, there was a proposal to change all the population=* tags on place nodes to reflect the overall metropolitan area’s population. The idea was that it would make it easier for OSM-only renderers like osm-carto to prioritize major cities where the population mostly resides outside the city limits, but the idea fell apart because there isn’t a neat one-to-one correlation between metropolitan areas and cities.
Some cartographers dream of being able to rely on OSM to say that, for example, San Francisco takes precedence over San José, so they suggest including the whole MSA. Except San José is in a different metropolitan area, so the whole CSA would be included in San Francisco’s population and the other cities just get the populations in their city limits. But this would result in the perverse situation where San José’s population gets transferred to a much smaller city 50 miles away in a different metropolitan area, only because that city is more famous. The global community has previously rallied against such arbitrary accounting tricks, preferring population=* to retain its more literal meaning.
A similar suggestion that sometimes comes up is to demote all the satellite cities to place=town and use place=city more judiciously. This is an elegant solution, but it doesn’t solve the edge cases. Again, if San Francisco becomes the only place=city in the Bay Area, it would erase the fact that San José suburbs like Gilroy have nothing to do with San Francisco. This problem tends to occur along major transportation corridors and along coasts, where the population doesn’t have a clear nucleus.
To the extent that a renderer or geocoder needs something more nuanced than a raw population within the city limits, it should look beyond OSM. Traditionally, data consumers like Mapbox have simply hard-coded preferences for some world-class cities over others. But a data consumer can produce more data-driven results by consulting the linked Wikidata items, which come with plenty of demographic and economic data on multiple axes that we don’t tag in OSM, along with data that can be used as proxies for notability, such as Wikipedia article page views.
Note that place=* does not specify the legal incorporation type of a municipality. Rather it indicates what type of place a settlement is in a more abstract general sense. A place=town can correspond to a municipality that is incorporated as a City®, Village®, Township®, Borough®, or Town® depending on the legal terms used in a given state. For example, an incorporated Village® in my area recently reincorporated as a City®, but regardless of legal status the appropriate place tag for this settlement is town based on the population and services available there.
At under 3000 residents place=village does seem appropriate for Vergennes. However, it does have a full size supermarket and serves as a small commercial hub for the immediate surrounding area (municipal boundary is just 2 square miles) so it could be considered a small place=town. It is incorporated as a City®, but that just means it uses a city form of government and is recognized as a city by the State of Vermont. Clearly it’s quite confusing that the terms City®, Town®, and Village® indicate specific legal status of a municipality while in OSM place tags these same words indicate settlement importance/size.
Since mappers really seem to want to record the type of government a municipality uses, perhaps establishing a separate key for this would be good. I’m imagining something like protection_title that indicates the type of protected area in freeform text (“State Park”, “Wildlife Sanctuary”, etc).
This comment stood out to me. I think it’s fine in principle for a settlement in a sparsely-populated area to have a higher place= value than the exact same settlement in a dense area. I.e. if these settlements are the most important features in the area, it makes sense for them to be more prominent than usual, and vice-versa. The devil is in the details of course about how to accomplish this.
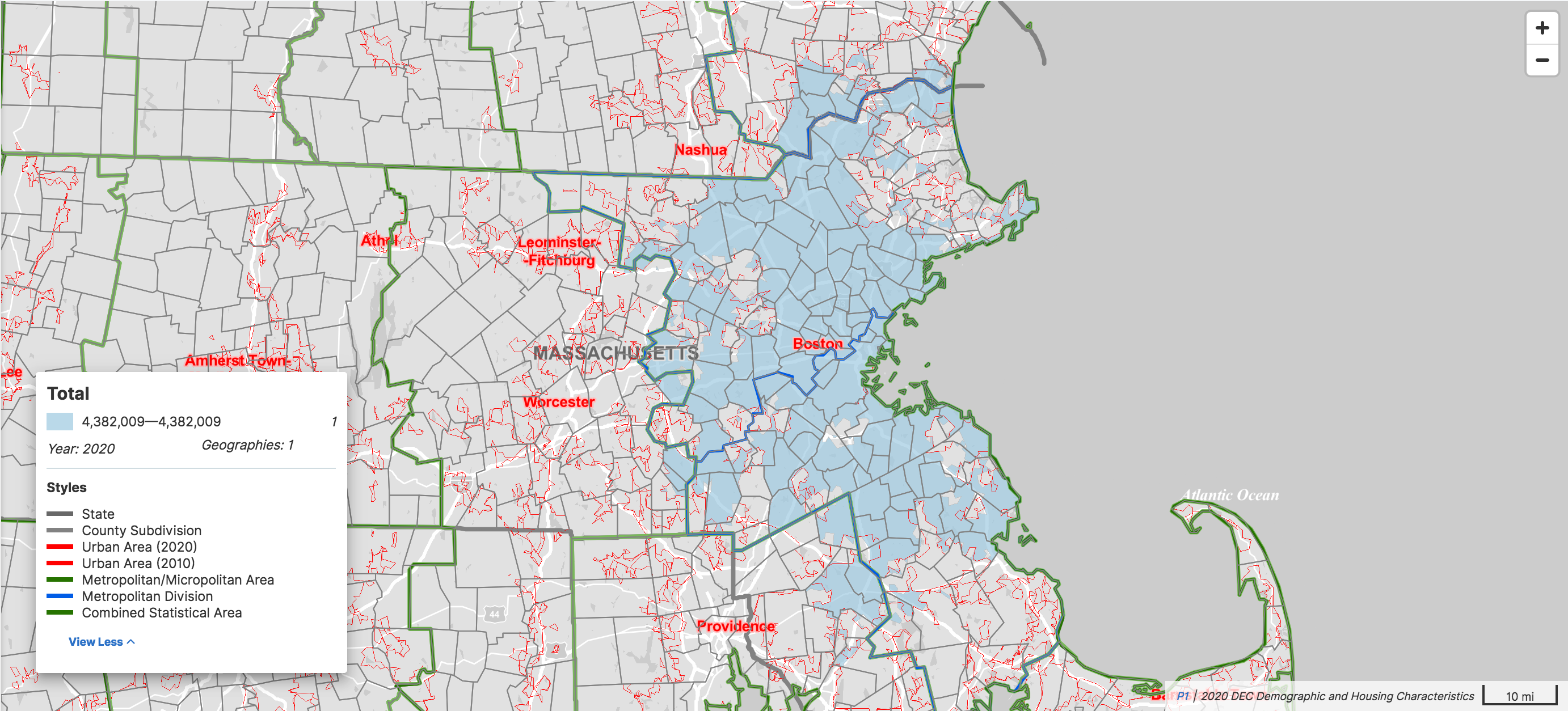
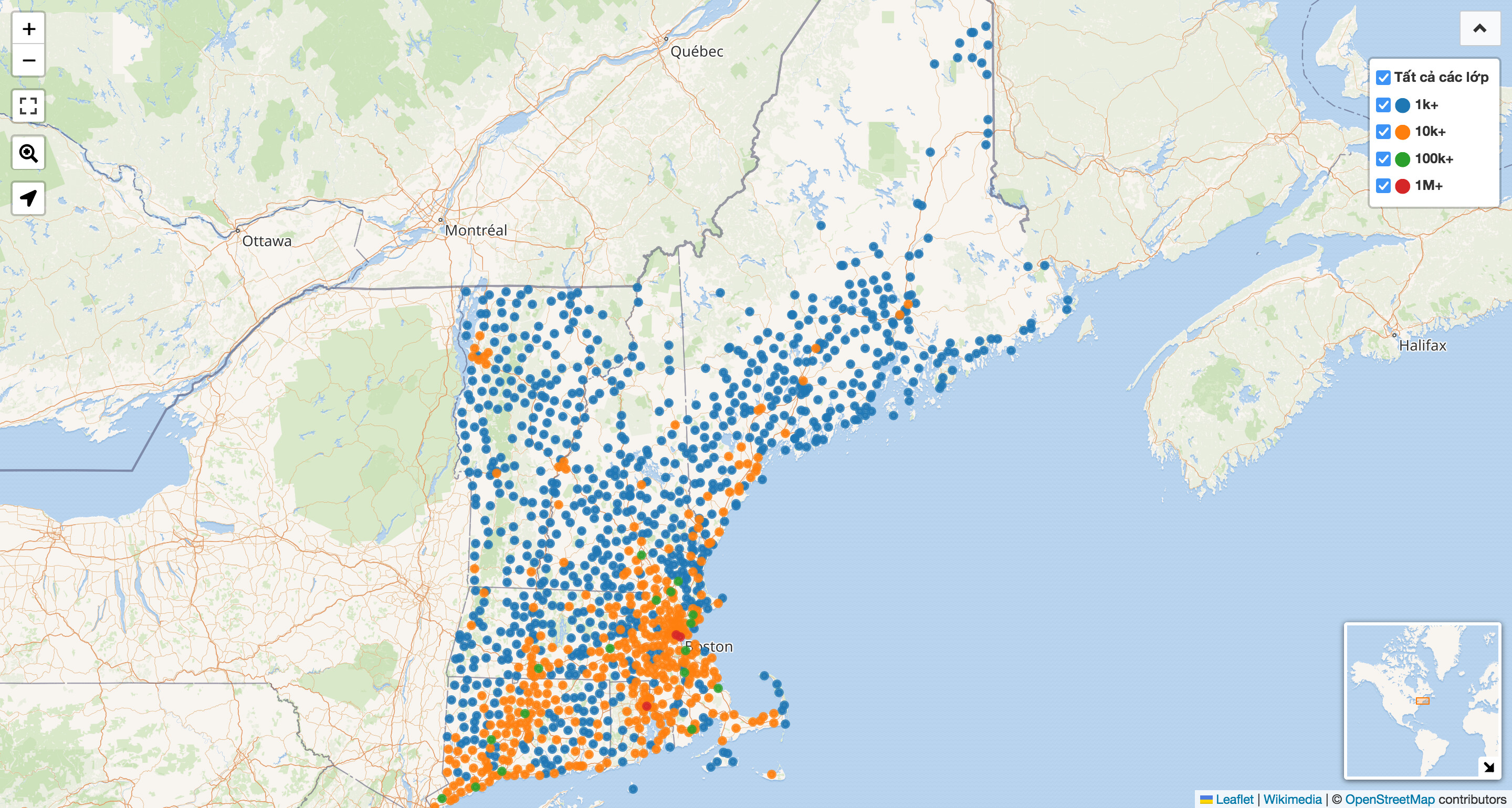
The San Francisco Bay Area foiled the last attempt at redefining population=*, but Boston is no less troublesome. If we ignore notability and economy and focus on population density for a moment, the Boston urban area would be the most appropriate statistical unit upon which to calculate a population for the purpose of label sizing. Urban areas are what many maps shade or highlight to represent a built-up area. But like many urban areas, Boston’s doesn’t follow any rational lines. It extends well beyond the Boston city boundary, even venturing into southern New Hampshire.
Ordinarily, metropolitan and micropolitan statistical areas do a decent job of answering the question, “Would a town in this area be considered a suburb of one of the principal cities?” Some large, multifocal statistical areas are further divided into metropolitan divisions to help answer the question of which principal city it’s a suburb of; San José–San Francisco–Oakland and Boston–Worcester–Providence are divided thus. But each of these structures fails to contain the Boston urban area:
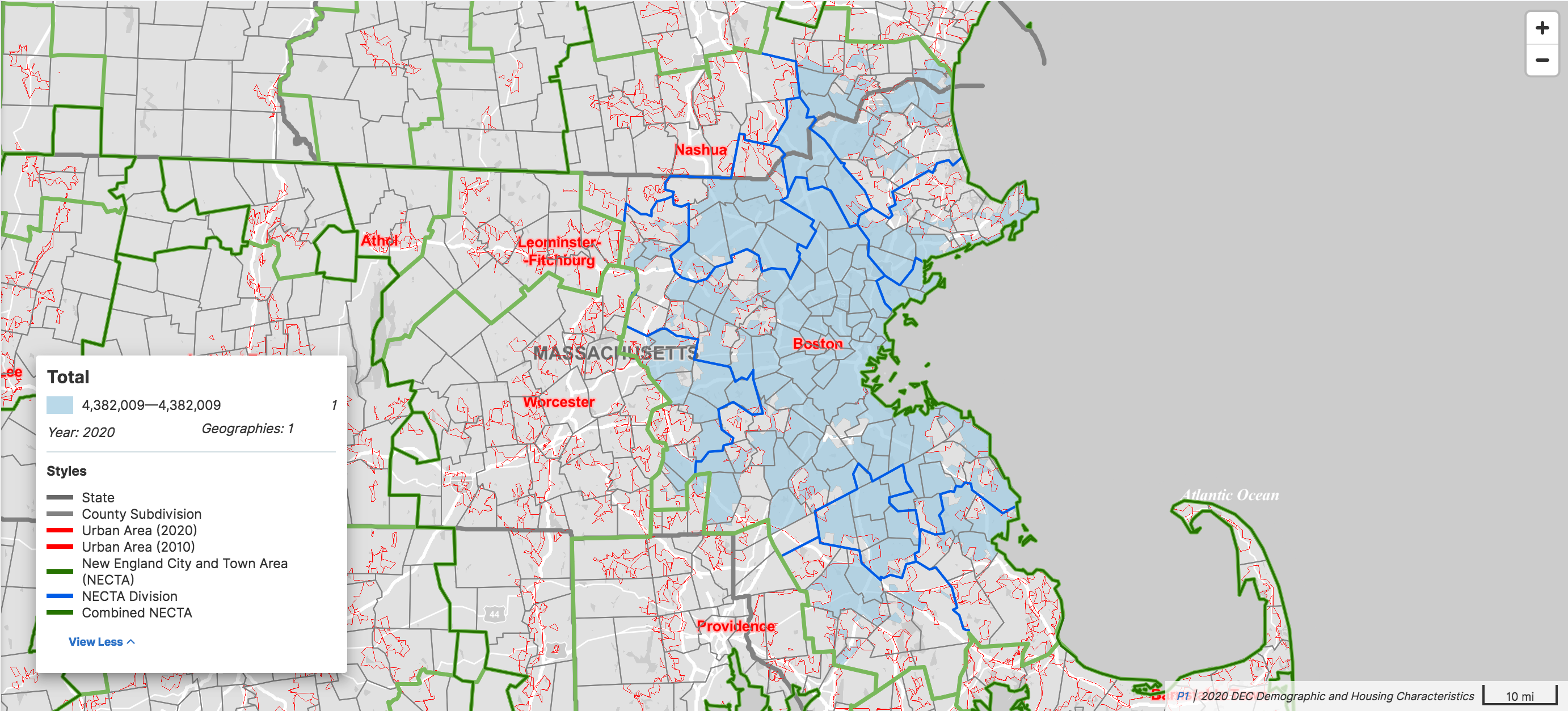
To some extent, we can chalk it up to the unusual town government structure in New England, which doesn’t really aim to reflect population growth. But NECTAs and NECTA divisions are not much better at containing the urban area:
The urban area comprehensively accounts for all the built-up area around Boston, but we probably shouldn’t tag population=* based on urban areas sometimes and based on administrative structures other times. Neither mappers nor data consumers would be able to intuit that distinction reliably, even if we could agree on which populations should be based on which heuristic.
For simplicity, we could rely solely on urban areas to determine population=* tags, but ignoring everything besides demographics creates problems of its own. Notice that “Leominster–Fitchburg” urban area to the west of Boston: lots of urban areas represent population centers that have conjoined over the years. In theory, we could fairly distribute the population=* among the multiple named cities, but that’s a lot of implicit original research for a single numeric tag.
Taking a step back, labeling populated places on a map is essentially a point clustering problem, just without the colored bubbles. When clustering points, you have to defer the decision to show or hide a label until the last possible moment. Baking this decision into the data means making assumptions that may not always hold. Whether or not you think Newport is an important city like Providence, it’s no problem that this map labels both at zoom level 6, because there’s enough room for both labels to fit comfortably. But if someone who doesn’t have perfect eyesight sets their phone to show text at a slightly larger size, suddenly Newport looks a little less essential at this zoom level.
The place points can be clustered based on their literal populations, but a sophisticated renderer can consult Wikidata for more nuanced data to support whatever fancy accounting tricks it desires. Wikidata already directly or indirectly links cities to their containing metropolitan statistical areas, which are tagged with up-to-date population figures. There’s nothing stopping Wikidata from even covering NECTAs and urban areas.
Boston, Cambridge, and Providence enter the exclusive million-plus club by virtue of the statistical areas that are named after them. After Boston and vicinity, there isn’t much work left to cover the rest of the New England. Tilesets generated by OpenMapTiles and Planetiler already run a similar SPARQL query against the Wikidata Query Service to retrieve translations of place names. A U.S.-focused tileset could quite reasonably adapt this query to pull in the enhanced populations seen here.
In that case, I’ll add one more requirement: the distribution of place=city nodes and of place=town nodes shouldn’t make the state’s borders very obvious if there isn’t an abrupt change in population density on the ground. Unless something about the water in New York discourages town-building, the state’s eastern border proves a need for reclassification, probably on the New England side. By contrast, things are looking OK in much of the rest of the country, despite a lack of hard-and-fast rules.
This is similarly an implicit goal of highway classification: some states like Kentucky and Louisiana include a much larger proportion of the public road network in their state highway networks than surrounding states do. For a couple years after the TIGER import and its literal mapping of route networks to highway=* values, you could easily make out the shape of Kentucky in the form of orange-colored roads – one of the more jarring qualities of OSM back in those days.
A municipality inherently has a boundary; the boundary relation’s border_type=* tag captures this official classification in an open-ended but still machine-readable format.
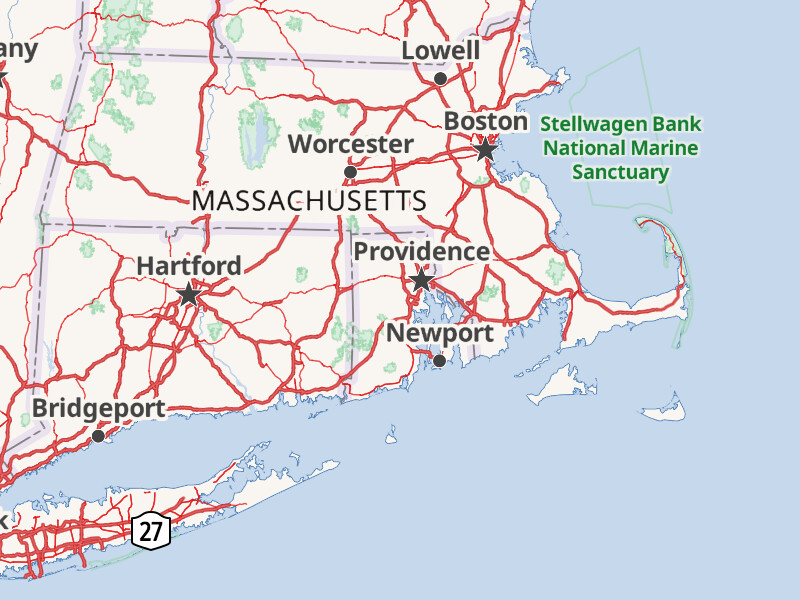
As a native Southern New Englander, this map brings a few surprises in its choice of which cities end up with a label.
Now while Newport is a city in the legal sense (has a head of government called
“mayor”, uses “City of” in its name, etc), it’s inclusion is out of place at this scale.
Instead, along that southern coast, I would expect to see the cities of New Haven, New London, and New Bedford (the English settlers were far from creative in their naming choices), as these places are certainly more significant population centers. Perhaps Newport might have more cultural prominence based on its popularity as a tourist destination, but that feels like a stretch.
My assumption is that this unexpected display choice is the result of label collisions from clustering algorithms. I can imagine that Providence collided out New Bedford’s label and therefore left room for Newport to be drawn. Bridgeport is much harder to explain, as New Haven is CLEARLY the more significant population center, and the missing New London makes even less sense.
Now if I were to stand in downtown Newport (something I do quite literally several times a week), the scene I see around me does not exactly scream “city” in any traditional sense. My pride would not be hurt if for these sorts of reasons we said “this is a city, but in OSM it’s a place=town” as part of a systematic reclassification.
I also note the missing Fall River label, which is certainly (and correctly) collided out by the Providence label. However, it’s definitely a city in the traditional and classic “looking around at downtown” sense and would make sense to encode as a city in the same way we would with San Francisco and Oakland, or Dallas and Forth Worth as distinct urban centers.
I’m hopeful that we can find a more systematic, if not algorithmic way to draw these distinction than just eyeballing things…
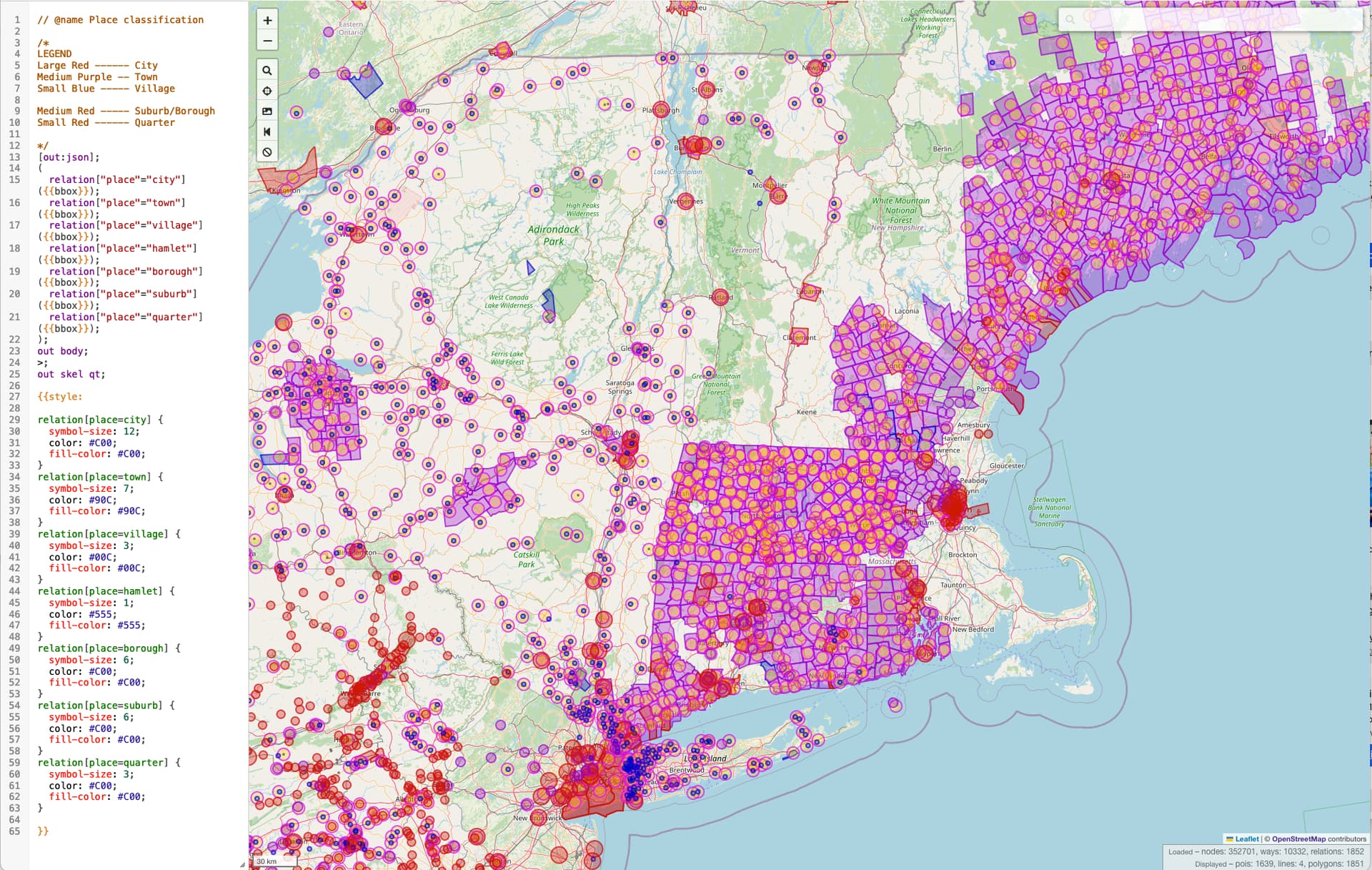
It turns out that the addition of place=* tags on the boundaries was something added by other users independently of the changes I reverted. Since it isn’t rendered by the Carto stack it wasn’t obvious that such tagging was used, but thanks for noticing! Adding place=* to boundaries is discouraged in the wiki, but we should probably take an active stand on that as it is duplicative and likely to get missed in any updating of place nodes.
Searching via OverPass it looks like New England also has a particular problem of place=* being placed on boundary relations.
Following up on this, I’ve removed the duplicative place=* tags from boundary relations in Vermont where a POI node with the place tag also exists. (changeset)
Broadly, we wouldn’t want to drop the place=* tag from a boundary relation if that is the only way the settlement is mapped, but having the tag on two objects is duplicative and likely to conflict when edits to one aren’t reflected in the other (as we just saw).
Yes, it’s essentially the result of clustering on the server side in OpenMapTiles, which is being opinionated without having any context about things like the font size or spacing between the icon and text label. Vector maps need the flexibility to make collision decisions on the client side at runtime, informed by more objective data.
Renderers don’t use place=* on boundary relations, but geocoders do. At State of the Map 2021, @lonvia gave a great overview of the challenges in supporting diverse place classification strategies in Nominatim. Geocoders need to work with places as areas of some sort, since you aren’t necessarily in a given city based solely on your proximity to its center. In the U.S., we aren’t mapping urban areas or postal cities, so OSM-based geocoders focus on administrative units. Nominatim recognizes place=* on the boundary relation, but we’ve already established that settlements can differ so markedly from administrative structures that conflating the two creates more problems than it solves. Alternatively, Nominatim can match the place node to the boundary relation based on wikidata=*, the label role, or some heuristics involving name=*.
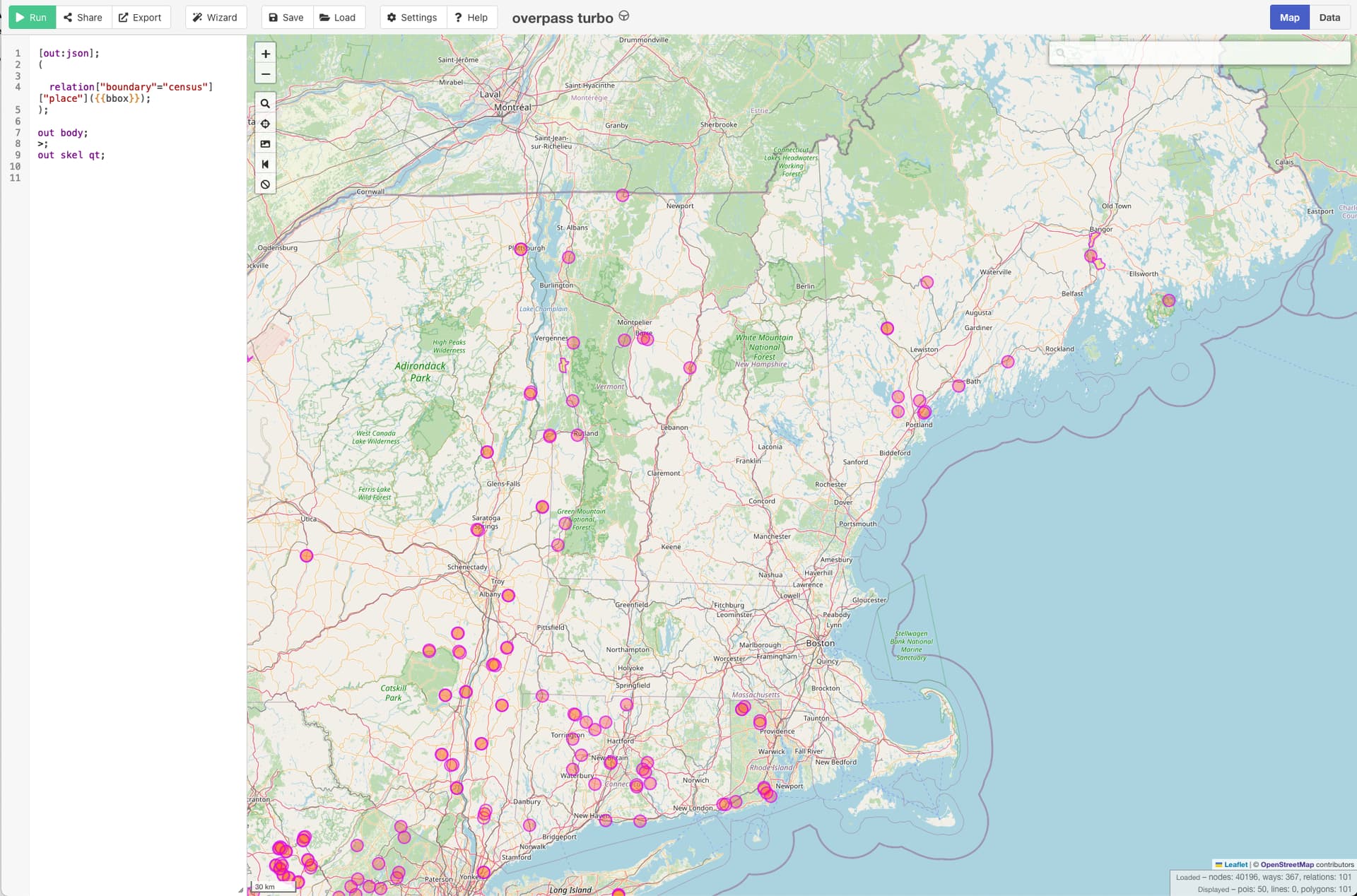
As you remove place=* from the boundary relations, make sure there’s some way for a geocoder to reassociate the boundary with a settlement if there’s a strong association in reality. For example, I regularly relate place=* POIs representing unincorporated areas with boundary=census relations representing CDPs while keeping them unrelated to boundary=administrative relations.
On the other hand, some place=* values represent space-filling places rather than population centers: county, state, and country are usually mapped as independent nodes at centroids, presumably as a compatibility shim for data consumers that don’t process boundary relations. I suppose place=municipality could be used in the same manner, but I haven’t bothered to do that. Instead, I’ve been distinguishing between Midwestern townships (analogous to New England towns) and other local places using border_type=* on the boundary relation.
If a boundary relation has a place tag, the relation includes a place node, and the boundary ways have a place tag, is it OK to remove the place tag from the relation and the ways? I’m seeing contradictions on many, probably because someone changed one or the other and didn’t realize it was duplicated.
This makes sense. Colorado has 4 types of Municipalities. You’re saying this could go in border_type, it doesn’t have to match the place node.
Yes, I agree that border_type=* can be used as stated here but it has gotten conflated with legacy “other things” and at least for land borders, isn’t very reliable. For maritime borders, it is more reliable.
I continue to believe that place=city should only be used for incorporated municipalities. There can be other things along with things tagged that which are “also true” (like it is a capital city, a consolidated city/county, an independent city, “named a town” (in California, “city” and “town” are synonymous by law), etc. But as “city” is so elastic, we should continue to insist that at least “incorporated” is true, considering we also use it for population=50000 to population=30000000 (or so…I don’t know what Tokyo is, something like that). That’s a wide range, and constraining “city” to at least “incorporated” (as we do so in the fifty states) keeps some sane, sensible bounds on things which are not especially tame to have bounds put on them.
Edit: Unless they already exist (and I think they do, at least are paid attention to by some renderers), it may be time for OSM (along with USA, EU, others…) to craft some “large_city” and maybe “mega_city” values for Earth’s 5M+ and 20M+ cities, for example. If / as renderers coalesce on these, paying attention to some consensus we (globally) hammer out, we win all around.
I’m not sure how much this rule would accomplish, other than blurring the line further between administrative areas and settlements. Not many unincorporated settlements are large and important enough to justify place=city anyways. But for example urban Honolulu is place=city by common sense, even though it’s unincorporated and only the surrounding county is considered a “city”. It’s similar to the situation in many New England towns and Puerto Rican municipios that aren’t fully urbanized.
What I am about to say is likely only true in many or most of the 50 US states. Not Australia, (though maybe aspects of this, as English Common Law has some overlaps, I’m not sure how much, I’m not sure where), not other non-USA places.
An incorporated city has received a charter from its state and is allowed to elect its own officials. It is a “body corporate” (similar to a corporation, but we might say “municipal law, not corporate law” or “municipal bond, not corporate bond”). Things like cities, towns, villages, charter townships (in Michigan) can be incorporated. It is not simple to explain in 50 words or less, but that’s largely it. Things vary from state to state (here, in the USA, where we attempt to apply this).
There isn’t a single answer for the whole country. In the context of this conversation, it would probably be more accurate to speak of municipalities rather than incorporated places. Unincorporated places have no direct self-government, though they may be served by any number of overlapping special-purpose districts (schools, fire protection, water, etc.).
A lot of this discussion has been about administrative units that are not populated places per se. A rural New England town or a Midwestern township or county has directly elected officials but (depending on the state) isn’t incorporated. All that means is that the administrative unit is legally part of the state government, rather than an independent municipal corporation organized under state law.
(Note that Puerto Rico is divided into municipios, which are kind of like New England towns rather than municipalities on the mainland.)
Getting likely a bit into the weeds here (with some readers), but you brought up municipios (in PR), Minh, and we document these in our wiki:
• “municipalities” exist in the 50 states, (not quite Hawaii, it can be explained, we do [1]) as usually- (always-?) incorporated bodies (which have been given their charter by their state and allow them to elect officials to govern “locally”),
• “municipalities” exist in the USA’s territories and commonwealths (non-state divisions more strongly associated with federal-level governance), where municipalities in these go by many different names:
Full disclosure in case you don’t already know this: Minh (and to a small extent, I) substantially wrote “Boundaries” (wiki), which is more descriptive, I and many others substantially wrote “US _admin_level” (wiki), which is more prescriptive. So, a lot of people have already said a great deal about this. We can say more, but the consensus we have achieved with these wiki and present (and ongoing) tagging isn’t exactly fragile, but it has been “carefully wrought,” and while it can be bent, it can also bend so much it can be broken.
Aw, shucks, I think my contributions to that page account for only a small fraction of what’s there now. In any case, the page is primarily about boundaries, which are only somewhat related to the populated places we’re classifying in this discussion.
New England is a head-scratcher when it comes to devising a hierarchy of populated places, but it’s downright easy compared to some other states when it comes to rationalizing boundaries into administrative “levels”.