The old site runs OSQA on an ancient version of django. The software is unsupported. The operations team are eager to turn off the django version of site and replace it with a static HTML site. The static HTML site can be generated using Hugo static site generator or similar, as per the wireshark converter.
I would like to help, but my current Internet connection is not strong enough to scrape every page and file on that site (that Wireshark code is basically a manual scrape of every page and file on the site)
I have another suggestion: since the database and files are still stored on the OSM server, can we expose that to the public through a simple API? From there, we can build a simple read-only interface to browse and navigate the Q&As.
tldr : keep the database and files on the OSM server, and replace Django with an ad-hoc API and a read-only user interface.
Another suggestion: share the osqa’s help.openstreetmap.org database dump here (focus on actual Q&A data; any private data could be simply left behind or anonymized first.). Maybe I can reconstruct a whole static Q&A site right from that database dump.
import requests
from bs4 import BeautifulSoup
import sys
import json
sys.stdout.reconfigure(encoding='utf-8')
start_page = 1
end_page = 88268
url_template = "https://help.openstreetmap.org/questions/{page}"
data = []
for page in range(start_page, end_page + 1):
print(page)
url = url_template.format(page=page)
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
element = soup.find(id="CALeft")
data.append({'id':page,'text':str(element)})
with open('qnadump.json', 'w') as f:
json.dump(data, f)
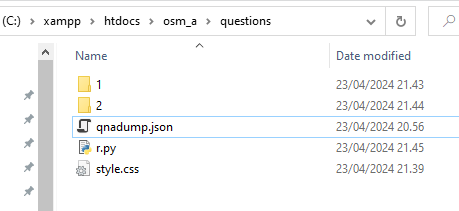
Then, copy qnadump.json, style.css, and r.py into the “questions” subfolder on htdocs.
r.py :
import json
import sys
import os
sys.stdout.reconfigure(encoding='utf-8')
with open('qnadump.json') as f:
data = json.load(f)
for i in data:
nya = '<meta charset="UTF-8"><link rel="stylesheet" type="text/css" href="../style.css">' + i['text']
os.makedirs(str(i['id']), exist_ok=True)
file_path = os.path.join(str(i['id']), 'index.html')
with open(file_path, 'w', encoding='utf-8') as file:
file.write(nya)
Run r.py there. It will generate a lot of folders, like this one (although I stopped the process after creating only two for this example below) :
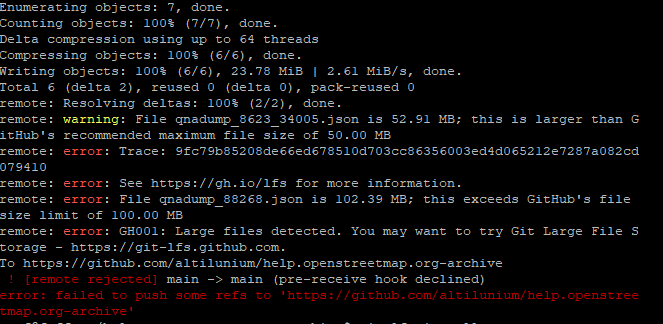
By using that shell account, I can create a static site clone. But where should I submit that static site so it can be deployed properly? (probably replacing the old Django-based help.openstreetmap.org with a static site)
C. Some of the files are still hosted on help.openstreetmap.org (and not scrapped). Make sure that all of this files are not deleted when turning off the OSQA django instance.