De gemeente heeft een zeer uitgebreide en vrij exacte dataset van een groot gedeelte van de bomen in Amsterdam, zo’n 270.000. Hiervan hebben nagenoeg alle bomen een geslacht (soort) toegekend (1.000 niet), een hoogte toegekend (8.000 niet) en een plantjaar toegekend (26.000 niet). Enige wat het grootste gedeelte niet heeft is een omtrek/diameter (190.000 niet).
Op dit moment zijn er zo’n 27.000 bomen aanwezig in OSM binnen de Gemeente Amsterdam. Hiervan zijn er ongeveer 18.000 ook aanwezig in de dataset van de gemeente. Deze 18.000 zullen dus moeten worden vervangen of worden bijgewerkt met de data van de gemeente (of niks mee doen en niet importeren kan ook natuurlijk).
(Dit getal 18.000 ben ik opgekomen d.m.v. QGIS door een buffer van 7,6 meter. Met een kleinere buffer krijg je meer dubbele bomen en met een grotere buffer verwijder je ook steeds meer bomen die niet aanwezig zijn in de dataset.)
Ik heb de tags van de dataset al omgezet naar tags die te gebruiken zijn in OSM. Dit is wat ik nu heb als tags (inclusief een aantal mogelijke waardes): denotation=natural_monument description=* diameter:range=0.1-0.2 m;>1.5 m genus=Ulmus genus:en=Elm genus:nl=Iep height:range=<6 m;15-18 m;>24 m leaf_cycle=deciduous;evergreen leaf_type=broadleaved;needleleaved name=* natural=tree operator=Begraafplaats De Nieuwe Ooster owner=Gemeente Ouder-Amstel ownership=municipal ref=* (dit is het referentienummer uit de gemeentelijke database) source=Gemeente Amsterdam source:date=2023-09 (dit is de laatste update datum van de dataset) species= Ulmus hollandica species:nl=Hollandse iep start_date=* taxon=Ulmus hollandica 'Belgica' taxon:nl=Hollandse iep (cultuurvariëteit) wikidata=* wikipedia=*
De referentie tag kan worden gebruikt voor het in de toekomst mogelijk updaten van de dan geïmporteerde data in OSM.
En als jullie betere benamingen voor sommige tags en/of keys weten dan hoor ik het graag!
Dan nog een vraagje, wat zijn de volgende stappen (indien de meerderheid van jullie hiermee akkoord gaat)? Gewoon deze stappen tot in detail volgen?
De Gemeente Amsterdam (hierna de Gemeente) verleent u hierbij een licentie voor het gebruiken en hergebruiken van de gedownloade dataset voor elk wettig doel. U mag de dataset zowel voor niet-commerciële als commerciële doeleinden gebruiken. U erkent hierbij dat deze licentie u geen auteursrecht of andere eigendomsrechten op de dataset geeft.
Bronvermelding
Bij hergebruik van de dataset is bronvermelding niet verplicht, al wordt dat wel op prijs gesteld indien mogelijk. U mag niet de indruk wekken dat de Gemeente de strekking van uw afgeleide werk onderschrijft. U mag geen officieel merkteken, embleem, logo of andere referenties van de Gemeente gebruiken zonder voorafgaande schriftelijke toestemming van de Gemeente.
Als u de dataset in originele of aangepaste vorm tegen betaling of gratis als dataset doorlevert of anderszins distribueert, moet u vermelden dat de originele dataset voor iedereen gratis beschikbaar is bij de Gemeente, onder deze Gebruiksvoorwaarden, die ook op de doorgeleverde dataset van toepassing zijn.
Klinkt als een goed plan. Het zou handig zijn om steekproefsgewijs de kwaliteit te bekijken. Bijvoorbeeld van 100 bomen de afstand van de dataset bekijken tot hoe het in het echt is.
Verder lijkt het mij wel handig om de huidige bomen bij te werken. Anders zit je in een situatie waar je maar een deel van een dataset hebt geïmporteerd en dat bemoeilijkt updaten later.
De conflictatie voor punten is gelukkig vrij eenvoudig. Gegeven:
A = { bomen OSM Amsterdam }
B = { bomen Amsterdam dataset }
Alles wat nog niet in OSM zit (B \ A) kan geïmporteerd worden.
Dan moet alles wat in beiden zit (A ∩ B) kan geüpdatet worden.
Het restant (A \ B) kan verwijderd worden.
De radius van 7,6 lijkt mij te veel. De afstand moet ruim minder zijn dan de maximale afstand die tussen twee bomen in de Amsterdam set zit. De range kan wel groter zijn maar dan moet je zorgen dat je voor elke boom in de range de dichtstbijzijnde pakt. Anders heb je risico dat bomen van plek wisselen.
Ik denk dat wij hieraan moeten voldoen door op deze pagina aan te geven dat we hebben geimporteerd en dat de orginele dataset bij de gemeente is te downloaden.
Een ding dat ik vergeten ben te vermelden. Er zijn zeker nog heel wat bomen die niet in de Amsterdam dataset zitten. De gemeente zelf vermeldt dat ze denken nog zo’n 500.000 bomen te missen (dit is inclusief alle bomen in het Amsterdamse Bos).
Er zijn hierdoor zo’n 9.000 bomen die wel in de OSM dataset zitten, maar niet in de Amsterdam dataset.
Is er een manier om op grote schaal bestaande nodes te vervangen voor nieuwe, waardoor de geschiedenis van de node bewaard blijft?
Zal ik doen! Ik zal hier laten weten wat daaruit komt.
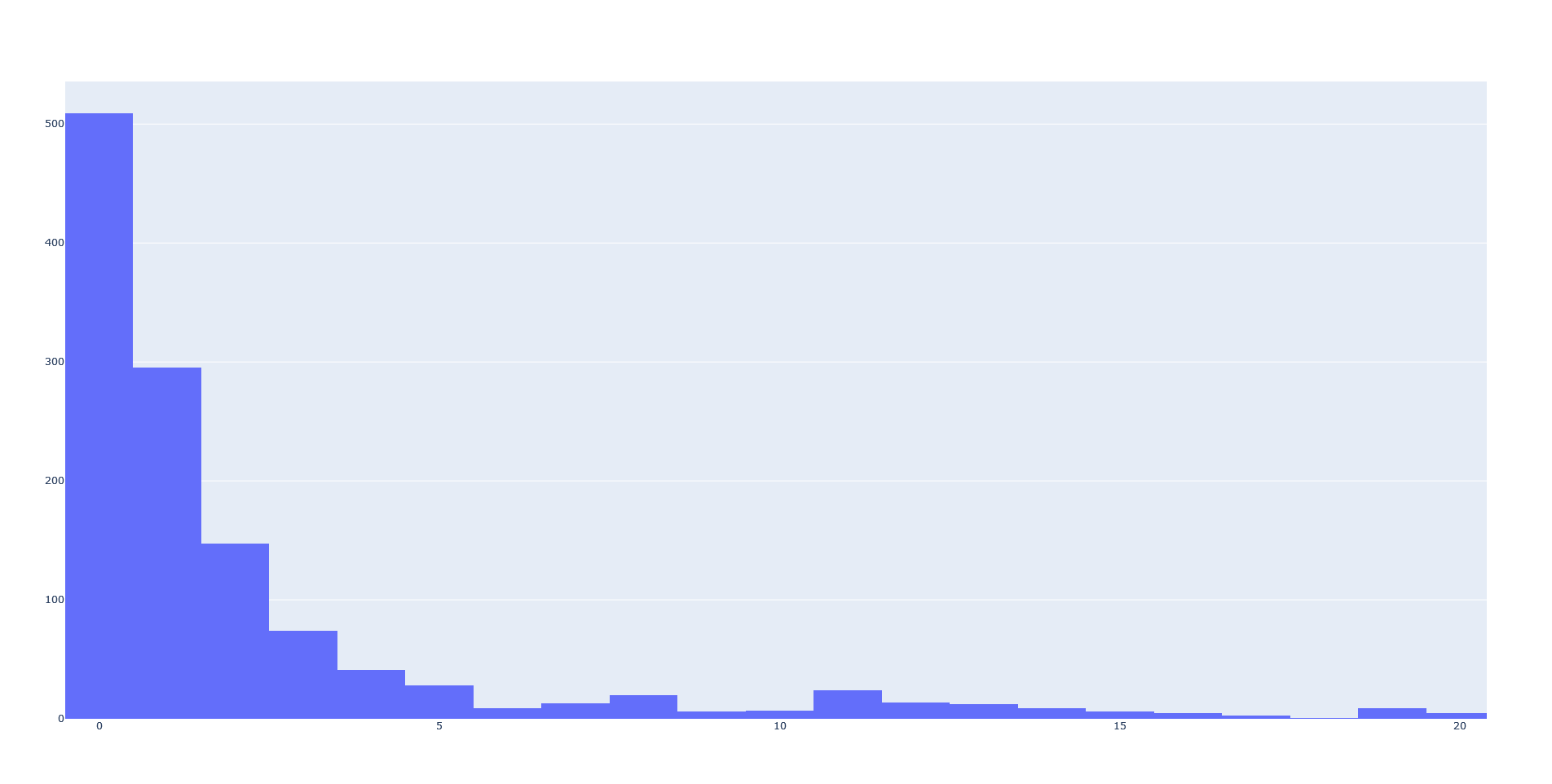
Ik heb wat bomen bij mij in de buurt gecheckt. Van de 97 bomen zijn er 89 binnen ongeveer 2 meter. En de overige 8 (hebben een vrij grote standaard deviatie en) liggen tussen de 2 en 8 meter.
Dus het overgrote gedeelte lijkt vrij goed te kloppen en een aantal niet echt. Dit komt ook overeen met wat ik nog heb gevonden op de site van de gemeente:
De nauwkeurigheid van de inmeting van de bomen is sterk wisselend: de afwijking ten opzichte van de werkelijke positie op straat varieert van 10 cm tot meer dan 10 m.
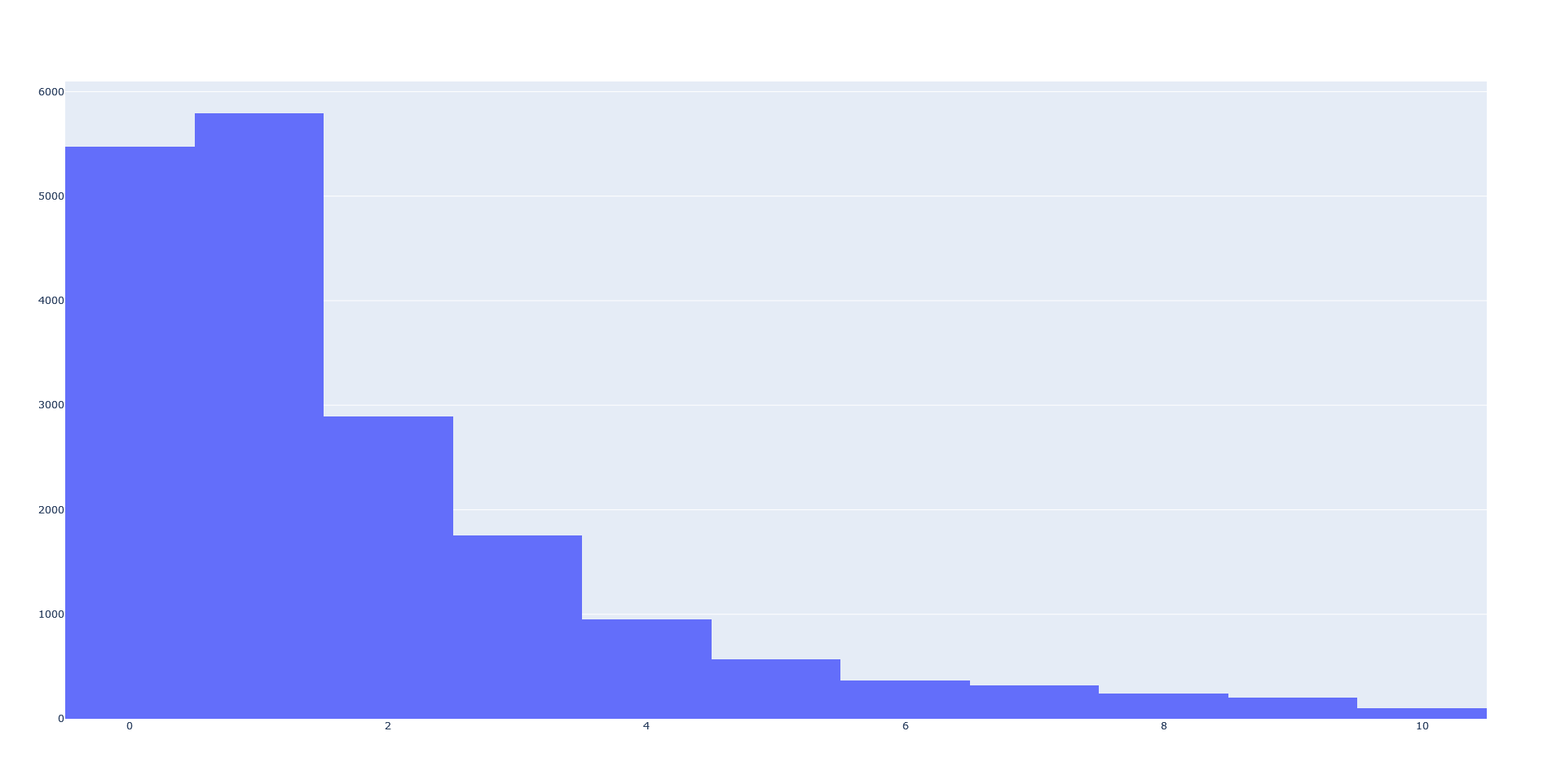
Hieronder ook wat info die ik met QGIS heb vergaard:
Het lijkt mij dat zeker alles binnen 2 meter aan elkaar kan worden gekoppeld binnen de datasets. En ik denk ook nog wel alles binnen 4 meter.
Hoe denken jullie hierover?
Heer eerlijk denk ik dat de meeste bomen door mappers zijn ingetekend op basis van de BGT of de AHN. En die zouden dan overeen moeten komen met de dataset van Amsterdam; waarbij die laatste véél vollediger is.
Ik kan het mis hebben natuurlijk; maar ik zou er geen traan om laten as je de door mij ingetekende bomen overschrijft met deze dataset en daarmee in één slag 10x zoveel bomen in OSM hebt staan. Scheelt toch 243.000 keer klikken…
Zouden jullie deze wikipagina kunnen beoordelen. Ik hoor het graag als mensen vragen en/of op-/aanmerkingen hebben.
Ik heb zelf wel een aantal vragen aan jullie:
Hoe/waar zoek ik dit uit: “ODbL Compliance verified: yes/no”?
Welke site kan ik gebruiken om de bewerkte dataset te uploaden, of is dit niet nodig?
Is “Data Reduction & Simplification” nodig voor deze import. Vlgs mij niet namelijk
De vorige vraag ook voor " Data Transformation Results"
Wat denken jullie dat de beste afstand is voor het wel of niet overschrijven van OSM bomen? Of op welke manier zou ik dit kunnen bepalen, hebben jullie hier ideeën over?
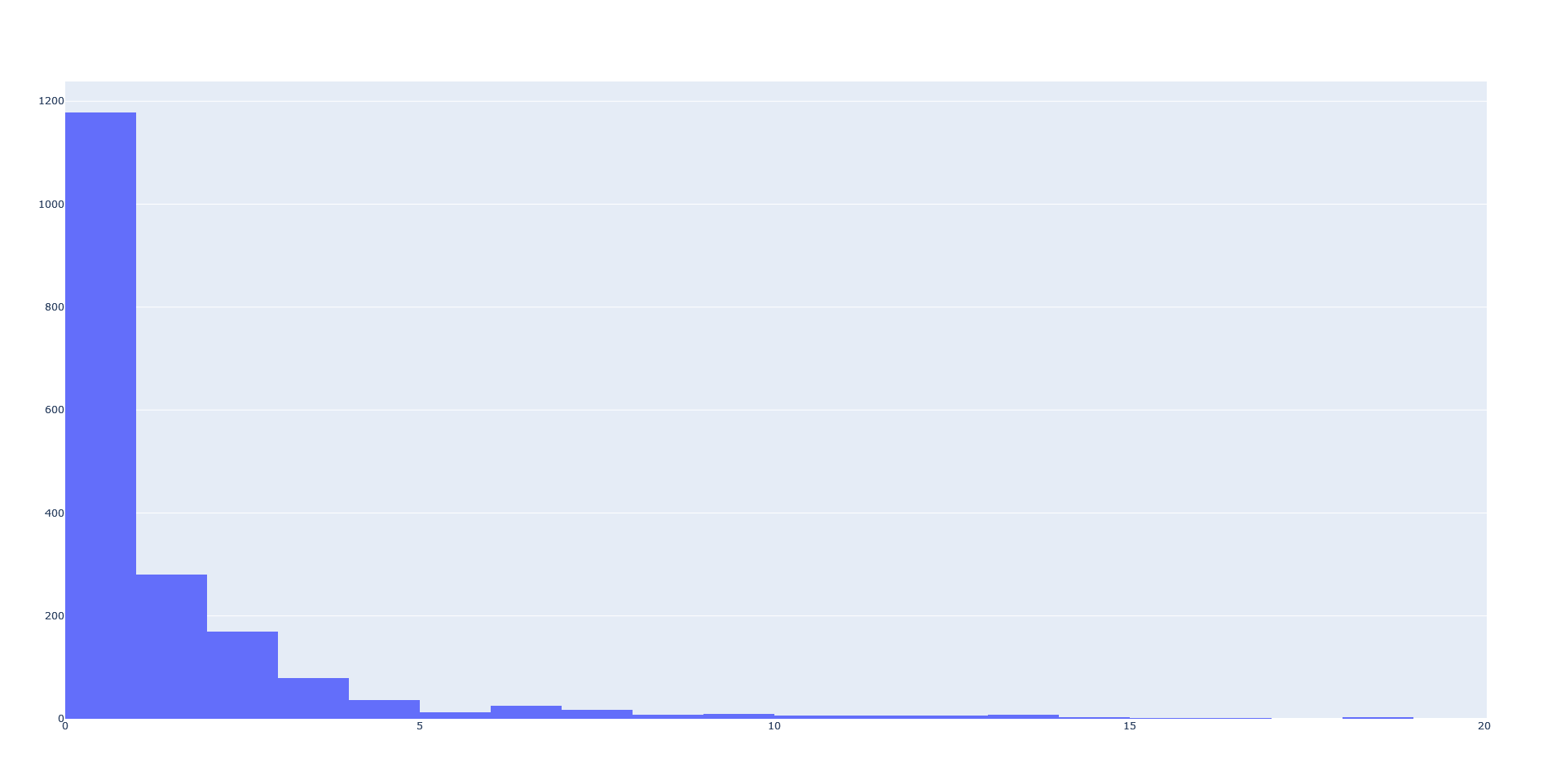
Ik weet nu namelijk alleen dat van de ~27.000 OSM bomen;
~9.000 binnen 1 meter liggen,
~13.000 binnen 2 meter liggen,
~15.500 binnen 3 meter liggen,
~17.000 binnen 4 meter liggen
van een boom in de te importeren dataset.
Wat is de maximum grootte van een import (in MB’s per keer)?
Extra vraagje, iemand heeft wat vragen achter gelaten op de discussion page. Is het de bedoeling dat deze op de discussion page worden geantwoord, of in het QA stukje op de wikipagina zelf?
Als het een terechte opmerking is kan je de tekst van de wikipagina verbeteren en dan op de de praatpagina zeggen dat je de tekst hebt aangepast. Ik geloof dat je ook een Opgelost-knop ergens hebt.
De licentie verifieer je zelf, dat is ofwel een rechtenverklaring die bij de dataset zit ofwel een expliciete toestemming die je voor de dataset hebt verkregen van de data-eigenaar. En dan link je daarheen.
Dit zou ik allemaal niet te zwaar maken voor een losse-puntendataset. Als de dataset en wat je gaat doen hier op het forum beschreven en besproken is, bv wat je wel en niet meeneemt (objectfilter), welke brongegevens je omzet naar welke tags, en hoe je gaat samenvoegen met bestaande OSM-data, dan kan je een samenvattingbericht hier plaatsen en vanaf de wiki daarnaartoe linken.
Of en hoe je de tussenbestanden en resultaatbestanden deelt daar zijn geen betonregels voor; vraag je kommentaar of wil iemand ze zien, dan kan je ze op een cloudlocatie delen (accountvrij).
Nu ik erover nadenk, een hoop bomen zijn waarschijnlijk als tree_rows en bosjes gemapt. Misschien heb ik het gemist, maar wat ga je daarmee doen?
Als eerste, dank voor je antwoorden en opmerkingen.
Op de wiki pagina onder Data Transformation heb ik beschreven op welke manier ik de dataset bewerk.
Hoh, hier had ik inderdaad nog niet over nagedacht.
tree_rows is redelijk makkelijk. Met QGIS kan ik een lijst maken van alle id’s van bomen rijen die op (bijvoorbeeld) minder dan 2 meters afstand liggen van de te importeren bomen. Deze id’s kan ik dan importeren naar JOSM daar nog even handmatig controleren en dan verwijderen. (Zal dit ook nog ff toevoegen aan de wikipagina.)
Bosjes is een stuk lastiger. Na wat rond te kijken met qgis, streetview en bgt zie ik dat er vrij grote verschillen zitten tussen bosjes. De ene zijn echt dichtbebost en worden in de bgt ook als bosplantsoen aangegeven. Maar weer anderen zijn in de bgt alle individuele bomen in kaart gebracht terwijl ik er toch niet zo makkelijk doorheen zou kunnen lopen.
En dan hebben we ook nog heel wat 3dshapes bosjes, die eigenlijk gras zouden moeten zijn met een paar bomen erop. Doordat er 8500 van deze vlakken in Amsterdam zijn (4500 hiervan 3dshapes) valt dit niet mee te nemen binnen deze import, want elk vlak zou je individueel moeten checken met een survey wat voor type bosplantsoen het is.
Dus ik zal hier niet op checken.
Ik zou gewoon de bomen over de landuse=forest/natural=wood heen importeren. Het is namelijk niet fout om een vlak als bos in te tekenen en de individuele bomen aan te geven.
Zie mijn eerdere bericht. Door deze vrij grote afwijking (dit is wel alleen op sommige plekken) heb ik ook in de import stappen meegenomen dat ik handmatig aan de hand van de BGT omtrekgericht (en eventueel ook luchtfoto’s) snel check of de bomen op de goeie plek staan.
Ik ben geen bioloog of bomenkenner. Dus kan daar eigenlijk geen uitspraken over doen. Maar van de paar bomen die ik wel van elkaar kan onderscheiden zie ik geen fouten. De andere informatie zoals hoogte en dikte zie ik van de bomen die ik heb gecheckt geen fouten.
De frequentie van het checken op bomen is om de 3 jaar. Dit betekent niet dat heel Amsterdam maar elke 3 jaar wordt gecheckt, maar dat de gemeente 3 jaar lang bezig is met de hele stad checken. Naar mijn inziens worden er halfjaarlijks updates uitgebracht, maar daar ben ik niet zeker van.
Ah duidelijk, ik was je eerste bericht even vergeten. Misschien wel goed om die disclaimer over de afwijking van de gemeente (10cm tot 10m+) op de wiki er bij te zetten. Als ik het goed heb gezien staat die er nu niet? Dat lijkt me wel een belangrijke.
De bgt is nogal wisselend, zeker als je NL-breed kijkt. Mijn eigen gemeente zet bomen er helemaal niet in, en een buurgemeente sommige wel sommige niet. Dus je hebt daar dingen als grasvelden die vol bomen staan, maar geen enkele in de BGT, en duidelijke bosgebieden waar ineens een deel van de bomen ook nog afzonderlijk er instaan.
Hoe dat in OSM staat is wéér een heel ander verhaal, maar vaak zit er behoorlijk wat werk in. Ik vind het eigenlijk wel zo netjes, als het tijdens de import niet opgelost kan worden, dat er een sluitende aanak is om dit binnen afzienbare tijd op te lossen.
Gewoon maar importeren en de afwijkingen en verdubbelingen (elkaar verdringende bomen die op een bos groeien) laten staan, dat lijkt op een 3dshapes-achtige aanpak, en daar hebben we nog steeds last van, dus dat zou ik liever niet zien.