This is a file I have prepared which shows the data after it was translated to OSM schema:
This was then converted to 30 sections for manageability and to ease collaboration. See the table on the import page.
License
I have checked that this data is compatible with the ODbL.
No specific license was provided, so I inquired with the data owner. They assured me there are no restrictions on the use of the data.
Abstract
This data source comes from the Waukesha County Land Information Systems and contains approximately 163,000 address points. The dataset contains: housenumbers, streets, zip codes, and post office cities. In addition, the state field was filled in.
PostOffice: converted to addr:city=* (as described on addr:city=* the postal service city is the name of the USPS post office that serves the address’ ZIP code)
UnitNumber and UnitType: some cases were deemed useful to tag separate units, such as semidetached housing with a shared housenumber, or for determining ranges of units in buildings in a complex with one shared housenumber. Individual unit numbers where tagged as addr:unit=* and ranges were tagged as addr:flats=*.
The dataset will be imported in several small “tracts” for manageability. Each tract should be conflated with buildings if applicable and then can be uploaded.
Addresses will be conflated with buildings in the areas where most of the building. This will be done using the JOSM conflation plugin. See the import page for more detail.
Getting Involved
If you are experienced with JOSM and would be comfortable using the conflation plugin and would like to help importing the data feel free to shoot me a message .
This proposal looks good to me overall. Thanks for keeping a copy of the permission somewhere persistent.
Address_Use (it was considered that building=* could be set from this, but this refers to address use, not building construction purpose)
As long as you’re conflating with buildings, you could map these values to building:use. Otherwise, perhaps you could spin off a MapRoulette challenge to find the right place to put values like “Pub/Rec/School” from the dataset.
addr:street=“Cth Vv” should probably be “County Highway VV” (second V capitalized) based upon name tag of street in OSM.
addr:street=“Bermuda Boulevard Up” should probably be “Bermuda Boulevard Upper” based on the name tag of the associated street in OSM. (General issue with Up vs Upper)
addr:street=“Campbell Traces” should probably be “Campbell Trace Road” based on the name tag of the associated street in OSM.
“Ush” in addr:street should probably be “United States Highway”
addr:street=“Wembly Circle Lw” should probably be “Wembly Circle Lower” based on the name tag of the associated street in OSM. (General issue with Lw vs Lower)
There are four addresses that do not have a addr:street tag (they also do not have an addr:city tag).
There are four additional addresses that do not have an addr:housenumber tag (and no nohousenumber=yes - although I think these really do have a house number in reality, it is just not in the data)
addr:street=“Walnut Hollow” should probably be “Walnut Hollow Court” based on associated street in OSM.
addr:street=“Green Dragonfly Isl” should probably be “Green Dragonfly Island” based on location (it is located on an island).
Has the county published a schema or specification for this dataset? Such specifications usually come with a full table of the abbreviations in use. That would be preferable to hunting for abbreviations in the dataset.
By the way, I love that the county has published the original proposal and final report describing the county’s addressing system. That could be very useful for OpenHistoricalMap.
addr:street=“Yorkshire Traces” should probably be “Yorkshire Trace” based on the name of the associated street in OSM. This seems to be a general issue with Trace vs Traces.
addr:street=“Arbor Drive Extension?” Not sure what this should not be, but there probably should be a “?” in the street name. This seems to be a general problem as there are 15 addresses where addr:street contains “?”
In general there seems to be quite a few cases where addr:street doesn’t match the current OSM streets, and where OSM seems to be wrong (according to the USPS). I presume you will detect these during the import and research what the correct tagging should be.
The following addr:street values probably need to have the letter after “Mc” capitalized:
Mcallister Way
Mccall Street
Mccarthy Drive
Mcclure Drive
Mccormick Drive
Mccoy Parkway
Mcdivitt Lane
Mcdowell Court
Mcdowell Road
Mcfarlane Road
Mcgregor Court
Mckenzie Road
Mckerrow Drive
Mckinley Drive
Mclaughlin Drive
Mclaughlin Road
Mcleavey Court
Mcmahon Road
Mcnally Lane
Mcpride Lane
Mcshane Drive
The following addr:street values probably need to have the letter after “Mac” capitalized:
Macallan Court
Macarthur Drive
Macaulay Drive
Macintosh Way
Mackenzie Court
Mackenzie Drive
Mackenzie Lane
Maclen Drive
Maclynn Court
Maclynn Drive
This addr:street doesn’t look right:
Lovers Ln;N124W16826 Lovers Lane
The above situation happens 22 times in the data. Oddly, the housenumber that has been inserted in the addr:street tag doesn’t always match the value of the addr:housenumber tag, and in some cases addr:street appears to contain two different street names, e.g.
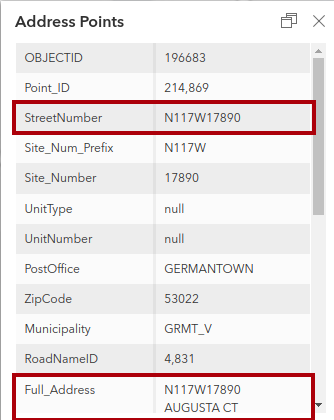
The original “street number” in the dataset looks like N117W17890, which I assume to be that address locator system the county uses. I think this last example would translate to 17890 Augusta Court and 11766 Medinah Court. I’ve never been sure what to do about a building that legitimately has two different addresses on two different streets. The least risky approach I’ve found has been to map two different address nodes within the building, but this doesn’t recognize that the two addresses are equivalent.
That is a reasonable value for this area. I think it is called grid addressing. It is also used in most of Utah.
Perhaps N117W17890 Augusta Court and W179N11766 Medinah Court. The full “grid identifier” is the housenumber.
If the building really does have two address (and they are not two different units within the building), then this is probably the best approach. I would check with local authorities.
Thanks @tekim for finding these the formatting errors. I’ll update the appropriate files in the coming days.
Indeed, part of the QA process is running JOSM/Plugins/FixAddresses which compares addr:street=* with the name=* of the nearby street. For this reason, I’m not too worried about finding all the incorrectly formatted street names, as any addresses which differ from the current street name in OSM will be flagged (I used the same process in my Milwaukee import, and it allowed us to find some names unfixed from the TIGER roads import, which is nice). Nonetheless it’s good for us to catch what we can now.
I’m not sure about all of those, at least Mackenzie and Macintosh seem right without the letter after “Mac” capitalized. I’ll have to look at these individually.
It’s a good idea (although it may be odd to see lots of building=yes + building:use=residential). I’ll take note of the potential for using this in the future, as at the moment I’d rather focus my attention to addresses.
I couldn’t find one. Would this help in any way that couldn’t be done by comparing with the surrounding road names? I could ask the data owner if it has enough of a benefit to us.
I guess a lot of this work has already been done, so it’s moot now. But maybe we missed something, so if they have documentation handy, it couldn’t hurt.
Of course all require investigation as to local use.
I have looked further into this and indeed in the original source data there are two address points at the same location (or as near as I can tell). I suggest they both be left in the data, and upon import, perhaps separated by a couple of meters for cartographic purposes. It would be interesting to talk to local authorities (or do some field work) to determine why this is done. Perhaps these are duplexes and there really are two separate residences in the same building?
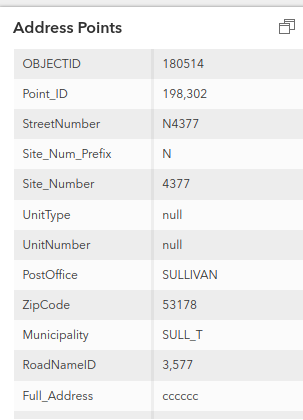
In the first case, it seems the StreetNumber does not appear in the Full_Address, but it is available in its own field, so it could have been pulled from there:
In the second case the Full_Address is obviously invalid, yet there is a StreetNumber and a PostOffice that should have made it into “cleaned_addresses.osm”:
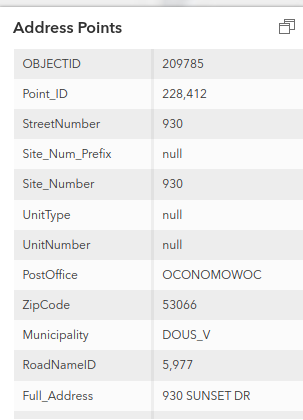
The third case is like the first, the Full_Address does not contain the StreetNumber, but all of the necessary information is present elsewhere:
In the forth case there doesn’t seem to be anything odd about the source record and yet in “cleaned_addresses.osm” there is only addr:state and addr:postcode:
I think this is unlikely. If we look at a more typical address point and compare the StreetNumber to the Full_Address, the StreetNumber is always the grid identifier for the street, followed by the house number.
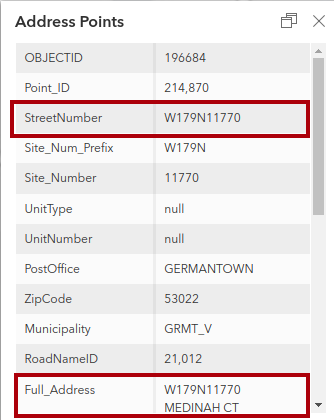
As I mentioned in another reply, there are two address points in the source data at the same location (as near as can be determined visually) here. I think we agree that, baring some insight from local authorities to the contrary, both should be represented in the final data to be imported - although that is an imperfect solution. Here is the source data for one of them (I have outlined the relevant parts in red):
My contention is that this should be tagged in OSM as:
addr:housenumber=W179N11766
addr:street=Medinah Court
(plus other relevant tags)
Here is the source data for the second one:
My contention is that this should be tagged in OSM as:
addr:housenumber=N117W17890
addr:street=Augusta Court
(plus other relevant tags)
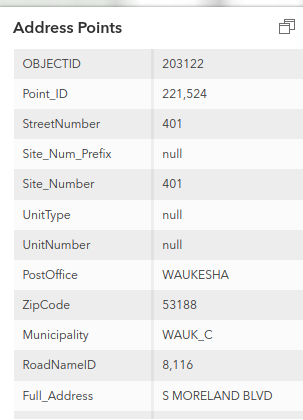
This approach is similar to how the address to the northwest was handled by the importers. Here is the original source data for this address:
Here is how this address was tagged in the proposed import data:
In fact there are 74,657 addr:housenumber tags that have a similar format (JOSM query “addr:housenumber”~“[1][0-9]+[NSEW][0-9]+.*$”) in the proposed import data out of a total of 163,290 addresses.
So my suggestion as to how the first two addresses should be tagged is consistent with the way the rest of the data in the proposed import is being handled.
Sorry, I was mistaken in thinking the import was generally mapping the Site_Number field to the addr:housenumber key rather than including the whole StreetNumber. This makes a lot more sense now. The USPS ZIP code lookup tool recognizes “W179N11766 MEDINAH CT” (though I can’t tell from aerial and street-level imagery whether these residences even get mail delivery). In terms of formatting, is it more correct to smoosh the two coordinates together, as the USPS does, or separate them by a space or dash, as seen in this article?
Both Medinah Court and Augusta Court are in a condominium development, which could explain the overlapping address points. (Ignore the links in this press release; the original development’s website has been repurposed for a similarly named development elsewhere.) In my neck of the woods in California, these are called “air parcels” and some GIS departments keep them in a layer separate from address points per se. I guess the ideal for OSM would be to scoot each address point toward the corresponding entrance, disregarding actual property rights, but obviously that isn’t something a bulk import could be expected to do in a first pass.
I don’t have a strong opinion (other than to be consistent within Wisconsin), but given the source data, the USPS data, and the way the proposer of this import has formatted the data, it seems like “smoosh” is the way to proceed.
It also recognizes “N117W17890 AUGUSTA CT”, so best to include them both, and as you suggest, when possible, move them apart and toward what we assume to be their applicable entrance.