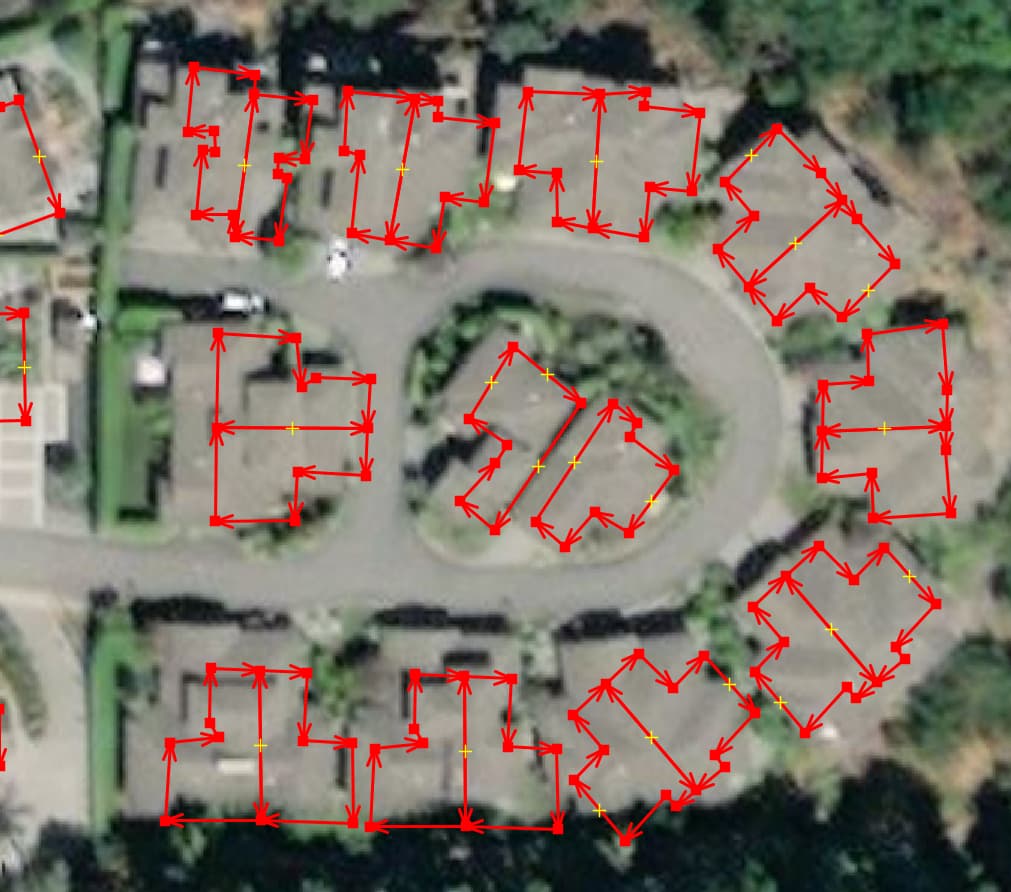
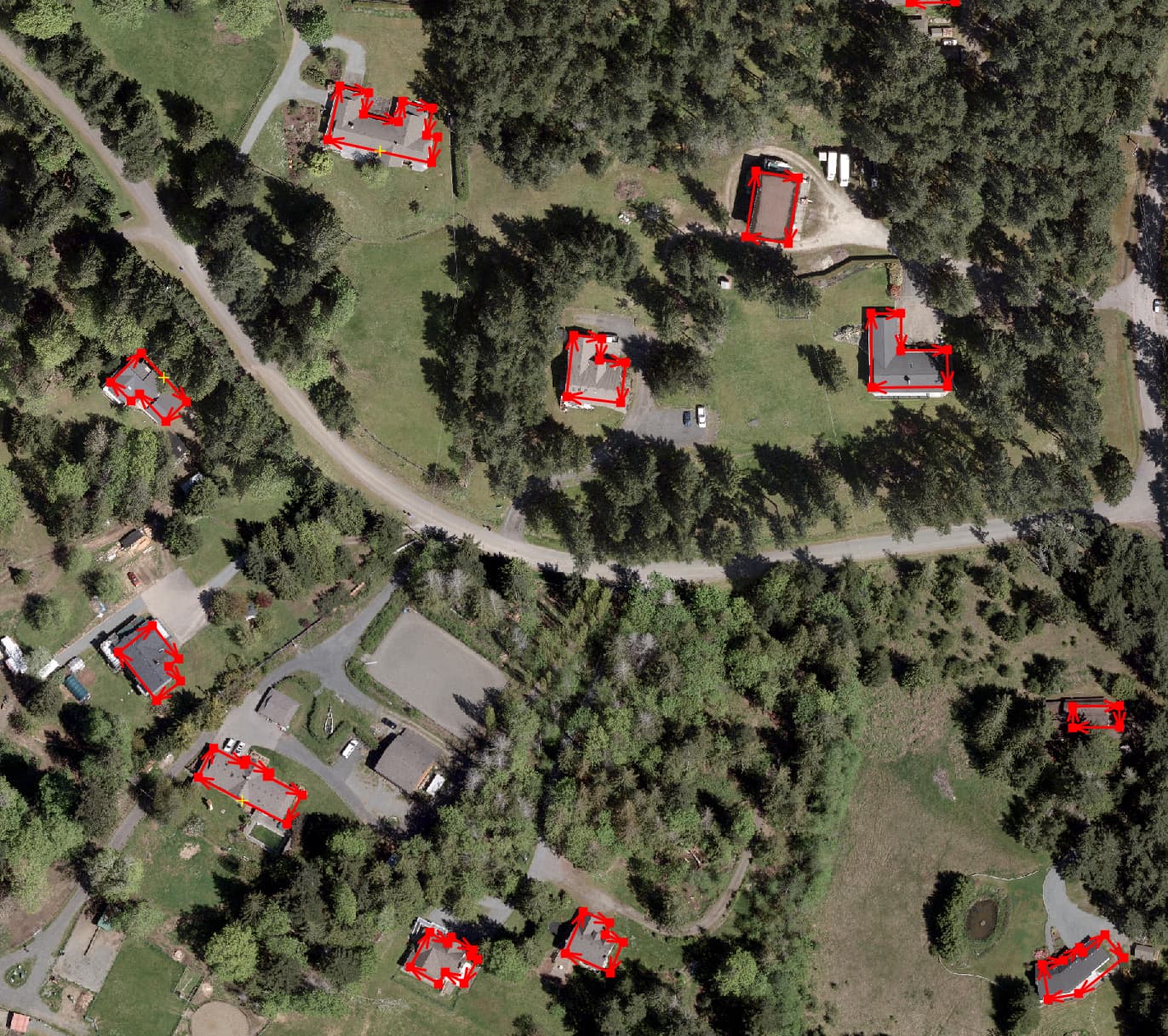
i did the addresses/houses for gabriola, mudge and de courcy islands today. these shapefiles are the interesting ones
https://www.rdn.bc.ca/sites/default/files/inline-files/AddressPoints_204.zip - 24476 points
https://www.rdn.bc.ca/sites/default/files/inline-files/BuildingFootprints_26.zip - 28457 polygons
also this one, but more for reference
https://www.rdn.bc.ca/sites/default/files/inline-files/Parcels_205.zip - 26398 polygons
first we need to convert these to geojson to work with them from the command line, note that the coordinates use a weird projection, check with ogrinfo -so -al AddressPoints.shp
ogr2ogr -f GeoJSON -s_srs EPSG:26910 -t_srs EPSG:4326 address.geojson AddressPoints.shp
ogr2ogr -f GeoJSON -s_srs EPSG:26910 -t_srs EPSG:4326 building.geojson BuildingFootprints.shp
ogr2ogr -f GeoJSON -s_srs EPSG:26910 -t_srs EPSG:4326 parcel.geojson Parcels.shp
next calculate the bounding box of the data and use overpass-turbo to get all street names and island names that already exist in osm in the area
//[out:json];
[out:csv("name"; false)];
(
way["highway"]["name"](49.025117666823995,-124.74795839676155,49.467606528264945,-123.68841269377428);
node["place"="island"](49.025117666823995,-124.74795839676155,49.467606528264945,-123.68841269377428);
way["place"="island"](49.025117666823995,-124.74795839676155,49.467606528264945,-123.68841269377428);
relation["place"="island"](49.025117666823995,-124.74795839676155,49.467606528264945,-123.68841269377428);
node["place"="islet"](49.025117666823995,-124.74795839676155,49.467606528264945,-123.68841269377428);
way["place"="islet"](49.025117666823995,-124.74795839676155,49.467606528264945,-123.68841269377428);
relation["place"="islet"](49.025117666823995,-124.74795839676155,49.467606528264945,-123.68841269377428);
);
out body;
//>;
//out skel qt;
and save it as streets.txt .
we need to convert street names in the addresses from NORTH RD (GabIsl) to North Road, which I did with this python code:
import json
from collections import Counter
import difflib
import sys
with open('streets.txt', 'r') as f:
known_streets = set(f.read().splitlines())
if len(known_streets) < 100:
sys.exit('Error: streets.txt is too short')
abbreviations = {
'LK': 'Lake',
'CAPT': 'Captain',
'HARELQUIN': 'HARLEQUIN', # typo
# https://www.canadapost-postescanada.ca/cpc/en/support/articles/addressing-guidelines/symbols-and-abbreviations.page
'ABBEY': 'Abbey',
'ACRES': 'Acres',
'ALLEY': 'Alley',
'AVE': 'Avenue',
'BAY': 'Bay',
'BEACH': 'Beach',
'BEND': 'Bend',
'BLVD': 'Boulevard',
'BYPASS': 'By-pass',
'BYWAY': 'Byway',
'CAMPUS': 'Campus',
'CAPE': 'Cape',
'CTR': 'Centre',
'CHASE': 'Chase',
'CIR': 'Circle',
'CIRCT': 'Circuit',
'CLOSE': 'Close',
'COMMON': 'Common',
'CONC': 'Concession',
'CRNRS': 'Corners',
'CRT': 'Court',
'COVE': 'Cove',
'CRES': 'Crescent',
# 'CROSS': 'Crossing',
'CDS': 'Cul-de-sac',
'DALE': 'Dale',
'DELL': 'Dell',
'DIVERS': 'Diversion',
'DOWNS': 'Downs',
'DR': 'Drive',
'END': 'End',
'ESPL': 'Esplanade',
'ESTATE': 'Estates',
'EXPY': 'Expressway',
'EXTEN': 'Extension',
'FARM': 'Farm',
'FIELD': 'Field',
'FOREST': 'Forest',
'FWY': 'Freeway',
'FRONT': 'Front',
'GDNS': 'Gardens',
'GATE': 'Gate',
'GLADE': 'Glade',
'GLEN&': 'Glen',
'GREEN': 'Green',
'GRNDS': 'Grounds',
'GROVE': 'Grove',
'HARBR': 'Harbour',
'HEATH': 'Heath',
'HTS': 'Heights',
'HGHLDS': 'Highlands',
'HWY': 'Highway',
'HILL': 'Hill',
'HOLLOW': 'Hollow',
'INLET': 'Inlet',
'ISLAND': 'Island',
'KEY': 'Key',
'KNOLL': 'Knoll',
'LANDNG': 'Landing',
'LANE': 'Lane',
'LMTS': 'Limits',
'LINE': 'Line',
'LINK': 'Link',
'LKOUT': 'Lookout',
'LOOP': 'Loop',
'MALL': 'Mall',
'MANOR': 'Manor',
'MAZE': 'Maze',
'MEADOW': 'Meadow',
'MEWS': 'Mews',
'MOOR': 'Moor',
'MOUNT': 'Mount',
'MTN': 'Mountain',
'ORCH': 'Orchard',
'PARADE': 'Parade',
'PK': 'Park',
'PKY': 'Parkway',
'PASS': 'Passage',
'PATH': 'Path',
'PTWAY': 'Pathway',
'PINES': 'Pines',
'PL': 'Place',
'PLAT': 'Plateau',
'PLAZA': 'Plaza',
'PT': 'Point',
'PORT': 'Port',
'PVT': 'Private',
'PROM': 'Promenade',
'QUAY': 'Quay',
'RAMP': 'Ramp',
'RG': 'Range',
'RIDGE': 'Ridge',
'RISE': 'Rise',
'RD': 'Road',
'RTE': 'Route',
'ROW': 'Row',
'RUN': 'Run',
'SQ': 'Square',
'ST': 'Street',
'SUBDIV': 'Subdivision',
'TERR': 'Terrace',
'THICK': 'Thicket',
'TOWERS': 'Towers',
'TLINE': 'Townline',
'TRAIL': 'Trail',
'TRNABT': 'Turnabout',
'VALE': 'Vale',
'VIA': 'Via',
'VIEW': 'View',
'VILLGE': 'Village',
'VILLAS': 'Villas',
'VISTA': 'Vista',
'WALK': 'Walk',
'WAY': 'Way',
'WHARF': 'Wharf',
'WOOD': 'Wood',
'WYND': 'Wynd',
'E': 'East',
'N': 'North',
'NE': 'Northeast',
'NW': 'Northwest',
'S': 'South',
'SE': 'Southeast',
'SW': 'Southwest',
'W': 'West',
}
def fix(name):
return {
'NANAIMO RIVER ROD': 'NANAIMO RIVER RD',
'TOMS-TURN-AROUND': 'TOMS TURN-AROUND',
'COHO': 'COHO BLVD',
'DEEP BAY RD': 'DEEP BAY DR',
'FRONTIER RD': 'FRONTIER DR',
'ALLVIEW RD': 'ALLVIEW DR', # this might be changing
'WILKS WAY': '', # new development
'McLEAN LANE': '', # need to draw it, but can't see it
'PRIVATE RD': 'WALLACE WAY', # at least that's what it's called on OSM
'PRIVATE RD': '',
'GOLD RD': '', # a large compound
'KORDONAN RD': '', # need to draw it, not sure I can see it
'ALPINE VIEW PL': '', # new development
'WILD RD': '', # new development
'KIRK RD': '', # this is weird, maybe Burbank Road was renamed
'CORAL PL': '', # a business
'ANGEL RD': '', # new hard to see road
'REMPEL RD': '', # new hard to see road next to it
'GRAFTON RD': 'GRAFTON AVE',
'WILLIAM ST': '', # new development
'DESPARD AVE EAST': 'DESPARD AVE', # east would make sense but a neighbor is still called Despard Ave
'TOAD RD': '', # tiny road maybe
'PITT RD': '', # no idea
'LOON LAKE MAIN RD': '', # middle of nowhere
'AVA PL': '', # new development
'SERENITY PL': '', # need to draw
'DAVENHAM RD': 'DAVENHAM DR', # surely the drive doesn't become a road?
'BEECH AVE': '', # new development
'BANYON DR': '', # same
'YELLOWPOINT RD': 'YELLOW POINT RD', # typo
'MAPLE RD': '', # new road in forest
'HARTMAN AVE': '', # should be Thompson Avenue
'KING AVE': '', # should be KIPP RD
'SANFORD WAY': '', # should be ELM RD
'SECOND AVE (Extension)': '', # no idea
'CLARK RD': '', # should be CLARK DR but might not even exist
'CLARK RD WEST': '', # should be CLARK DR WEST? but might not even exist
'SHALE RD': '', # new development
'COPELY RIDGE DR': '', # new development
'BROAD RIDGE PL': '', # new development, could be added already
'RIDGE RD': 'SYWASH RIDGE RD',
'MANHATTEN WAY': 'MANHATTAN WAY', # typo
'OCEAN BLUE PL': '', # new development
'VALMAR RD': '', # house at the end of a road called Northwind Drive
'BATH ISLAND': 'SEAR ISLAND', # wrong island for some reason
}.get(name, name)
def de_specify(name):
return name.split(' (')[0]
def title(word):
if word.startswith('Mc'):
return 'Mc' + word[2].upper() + word[3:].lower()
if word == 'MCQUARRIE': # typo
return 'McQuarrie'
if word == 'MACKENZIE':
return 'MacKenzie'
if word == 'MACMILLAN':
return 'MacMillan'
if word == 'MACISAAC':
return 'MacIsaac'
if '-' in word:
return '-'.join([title(w) for w in word.split('-')])
if not word:
return word
return word[0].upper() + word[1:].lower()
seen_words = Counter()
def de_abbreviate(name):
if name == 'JUAN DE FUCA BLVD':
return 'Juan de Fuca Boulevard'
words = name.split(' ')
seen_words.update(words)
if words[0] == 'ST':
# short for "Saint", not "Street", uncapitalizing disables de-abbreviation
words[0] = 'St'
words = [title(abbreviations.get(w, w)) for w in words]
return ' '.join(words)
def extract_street_names(geojson_file, output_txt, edited_txt):
with open(geojson_file, 'r') as file:
data = json.load(file)
street_names = set()
for feature in data['features']:
if 'ROAD' in feature['properties']:
street_names.add(feature['properties']['ROAD'])
with open(output_txt, 'w') as raw_file, open(edited_txt, 'w') as edited_file:
for name in sorted(street_names):
raw_file.write(name + '\n')
new_name = de_abbreviate(de_specify(fix(name)))
# if name != new_name:
if name != new_name and new_name not in known_streets:
print(name, '->', new_name, file=sys.stderr)
matches = difflib.get_close_matches(new_name, known_streets, n=3, cutoff=0.6)
for m in matches:
print(' ', m, file=sys.stderr)
print(name)
edited_file.write(new_name + '\n')
# if :
# print(new_name, file=sys.stderr)
abbr_counts = {w: c for w, c in seen_words.items() if w in abbreviations}
# print(json.dumps(abbr_counts, indent=2), file=sys.stderr)
extract_street_names('address.geojson', 'streets_original.txt', 'streets_edited.txt')
which you can save as extract_street_names.py and run like this
python3 extract_street_names.py > unknown_streets.txt 2> why_unknown.txt
creating two files of missing street names, one of just the original street name, the other mapping the original name to the guessed missing name as well as 3 suggested similar looking osm names that might be a match.
all 1470 street names should be checked by hand. Of the 130 streets that are not in osm, reasons for a street name not being in osm:
- apostrophes -
Dragons Lane in osm vs. Dragon's Lane in the data and spaces like in osm Crows Nest Road instead of CROWSNEST ROAD in the data, i updated street names on osm to match rdn
- unrepeated letters like
Pickerel Place instead of PICKERELL PL or GARRY OAK
- mistakes like
NANAIMO RIVER ROD and mistakes like DEEP BAY RD instead of DEEP BAY DR in the data
- discrepancies between CIVIC and ROAD, for example
210 COHO BLVD has just COHO as its ROAD
TIMOTHY DR is Timothy Road on osm.DAVENHAM RD comes from DAVENHAM DR but in osm it’s just Davenham Drive throughout, there are other cases where addresses on the same road are DR and others are still RD- missing road names in osm
- new roads and new development that has addresses but no houses yet, like
BROAD RIDGE PL
- roads have
EAST or WEST in the name like PARKER RD EAST, usually in the data and not in osm, i added it to them on osm as well
PRIVATE RD
from unknown_streets.txt we can then generate a geojson file of only the address points that have a road name that is missing from osm to manually review with this python
import json
def filter_streets(input_geojson, street_list, output_geojson):
with open(input_geojson, 'r') as file:
data = json.load(file)
street_set = set(street_list)
filtered_features = [
feature for feature in data['features']
if feature['properties'].get('ROAD') in street_set
]
data['features'] = filtered_features
with open(output_geojson, 'w') as file:
json.dump(data, file, indent=4)
with open('unknown_streets.txt') as f:
street_list = f.read().splitlines()
filter_streets('address.geojson', street_list, 'missing_street_address.geojson')
i modified the python and osm until there’s no more missing streets. there may be an edge case of a short road name incorrectly converting to something it shouldn’t. validating that all addresses are next to roads in their address would be good.
now we can use streets_edited.txt to convert rdn data to osm’s addr format:
import sys
import json
with open('streets_original.txt') as orig, open('streets_edited.txt') as new:
orig_streets = orig.read().splitlines()
new_streets = new.read().splitlines()
rename_street = {orig: new for orig, new in zip(orig_streets, new_streets)}
def convert_to_osm_address_nodes(geojson_file, output_file):
with open(geojson_file, 'r') as file:
data = json.load(file)
osm_nodes = []
for feature in data['features']:
properties = feature['properties']
if not properties['ADDRESS']:
print('Address missing: ' + str(properties))
sys.exit(1)
street = rename_street.get(properties['ROAD'], properties['ROAD'])
if not street:
continue
new_properties = {
'addr:housenumber': properties['ADDRESS'],
'addr:street': street,
}
if properties['UNIT_NO']:
new_properties['addr:unit'] = properties['UNIT_NO']
feature['properties'] = new_properties
osm_nodes.append(feature)
data['features'] = osm_nodes
with open(output_file, 'w') as file:
json.dump(data, file, indent=4)
convert_to_osm_address_nodes('address.geojson', 'osm_address_nodes.geojson')
So now we have a nice osm_address_nodes.geojson file of addresses ready to be uploaded to osm. we now want to join these addresses to the building polygons.
For buildings we have this:
$ jq -r .features[].properties.Structure_ building.geojson | sort | uniq -c | sort -h -r
20827 Single Family Dwelling
4920 Detached Garage
1123 Mobile Home
584 Barn
473 Commercial
179 Industrial
130 Community Facility
53 Multi-Family Dwelling
35 Mixed Use
31 School
18 Fire Hall
17 Cabin
12 Utility Bldg
12 Shop
9 Shed
7 Duplex
5 Studio
4 Multi-use
4 Accessory Building
3 Water Reservoir
3 Storage Building
3 Pumphouse
2 Church
1 Workshop
1 Utility Building
1 Hatchery
Address points and building polygons often don’t match up, especially on De Courcy Island and Mudge Island.
At this point I reduced the amount of work by only looking at Gabriola, Mudge and De Courcy Islands. After moving address nodes around and performing a spatial join using something like this:
import sys
import geopandas as gpd
addresses = gpd.read_file("address.geojson")
buildings = gpd.read_file("building.geojson").drop(columns=["STArea__", "STLength__"])
mapping = {
"Single Family Dwelling": "house",
"Detached Garage": "garage",
"Barn": "barn",
"Commercial": "commercial",
"Community Facility": "public",
"Mixed Use": "mixed_use",
"Fire Hall": "fire_station",
"Mobile Home": "static_caravan",
"School": "school",
"Shop": "retail",
}
buildings["building"] = buildings["Structure_"].map(mapping)
buildings = buildings.drop(columns=["Structure_"])
if buildings["building"].isnull().any():
print("Error: Unmapped building types found.")
sys.exit(1)
joined = gpd.sjoin(buildings, addresses, how="left", predicate=None)
buildings_with_address = joined[joined["index_right"].notnull()].copy()
buildings_without_address = joined[joined["index_right"].isnull()].copy()
used_indices = set(joined["index_right"].dropna().astype(int))
addresses_without_building = addresses[~addresses.index.isin(used_indices)]
num_addresses = len(buildings_with_address) + len(addresses_without_building)
if num_addresses != len(addresses):
print(f"lost {len(addresses) - num_addresses} addresses")
num_buildings = len(buildings_with_address) + len(buildings_without_address)
if num_buildings != len(buildings):
print(f"lost {len(buildings) - num_buildings} buildings")
duplicate_indices = buildings_with_address[
buildings_with_address.duplicated(subset="index_right", keep=False)
]
if not duplicate_indices.empty:
print("same address mapped to different buildings")
buildings_without_address.drop(columns="index_right").to_file(
"buildings_without_address.geojson", driver="GeoJSON"
)
buildings_with_address.drop(columns="index_right").to_file(
"buildings_with_address.geojson", driver="GeoJSON"
)
addresses_without_building.to_file(
"addresses_without_building.geojson", driver="GeoJSON"
)
print("raw:")
print(buildings["building"].value_counts())
print()
print("no match:")
print(buildings_without_address["building"].value_counts())
print()
print("at least one:")
print(buildings_with_address["building"].value_counts())
print()
print("extra:")
# print(
# buildings_without_address["building"]
# .value_counts()
# .add(buildings_with_address["building"].value_counts(), fill_value=0),
# )
extra = (
buildings["building"]
.value_counts()
.sub(
buildings_without_address["building"]
.value_counts()
.add(buildings_with_address["building"].value_counts(), fill_value=0),
fill_value=0,
)
)
print(extra[extra != 0])
print()
i map each building type to their corresponding types in osm:
- Single Family Dwelling:
building=house
- Detached Garage:
building=garage
- Barn:
building=barn
- Commercial:
building=commercial
- Community Facility:
building=public (or more specific tag if applicable)
- Mixed Use:
building=mixed_use
- Fire Hall:
building=fire_station
- Mobile Home:
building=static_caravan
- School:
building=school
- Shop:
building=retail (or more specific tag if applicable)
strangely, parks have addresses. i decided to add them to osm as points as well. there’s a noticeable number of buildings that you can see in the imagery that are not in the rdn data.