that would help! Though for some things you still need to download entire object, without that editor will not have info on which side there is a water ![]()
actually, rereading the initial post, it seems this is already a multipolygon, so my suggestion is to not download the whole of it when you edit in the area.
It is a pretty big lake, you can even still see it on zoom 2 (also due to it being far from the equator), so it is expected to consist of many ways and these of many nodes.
Earlier we had some very big lakes mapped as natural=coastline, but it is not accepted any more I believe, see for example lake Superior which was converted to natural=water 7 years ago: https://www.openstreetmap.org/way/158598650/history
2 Likes
I’d generally agree, but I think there’s a danger of “false precision” in OSM editing, and this lake looks like an example of that. Here’s 51.33607,-73.16470 at z20:
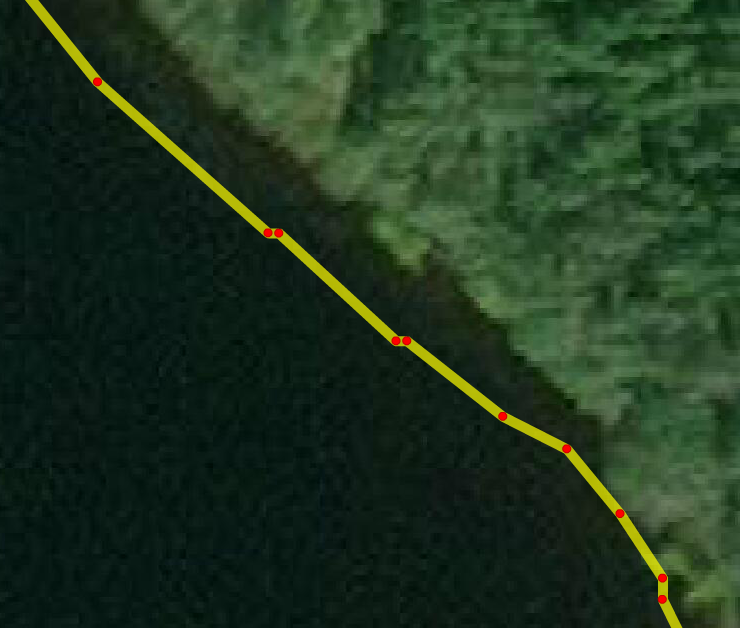
You can see there are unnecessary extra nodes in pairs, and in fact the boundary doesn’t really match the imagery at all. That’s not really surprising - lake boundaries erode and silt up, changing from year to year. But it shows that we need to be wary of investing this geometry with a high-precision status that it doesn’t really merit. Several of those nodes could be removed without making OSM any less accurate a representation of ground truth.
(I’m reminded of the over-noding that’s prevalent in a few patches of TIGER data: IIRC Tennessee is particularly bad for this.)
10 Likes
Oh, @Richard, the entire project has quite a bit of such noisy data, I think that is clear. This is definitely one of those endeavors of “the more we look, the more we’ll find.” Quality assurance (and the usual concomitant quality improvement) tends to work like that.
I think at least part of what has emerged in this thread is that there are times and places to improve noisy data, after all, they are noisy and we (usually) know how to remove such noise. It might be a lot of (tedious, time-consuming) work, but it is the correct thing to do. Also, there shouldn’t be a flippant reaction of (human) editors to “simplify this beast, it eats my (software) editor alive!” Good suggestions (Wireframe View, shoveling more RAM at the software editor, multipolygonizing-to-≤2000-nodes-per-way…) abound, let’s use those where we can. A “rush to simplify?” Mmmm, let’s not be too hasty with that, please, OSM.
4 Likes
yes, removing false precision is a good idea - especially such doubled nodes are a good example
as long as real data is not lost
6 Likes
I don’t want to weigh in on the question if this is overnoded or not, but the bit I don’t get is why this would have a performance impact on JOSM. One of the nice things about OSM MPs is that you -don’t- need to have them completely loaded as long as you are making local geometry changes.
3 Likes
yes, without knowing the actual shoreline geometry, this is apparently not aligning well with this specific aerial image (but the actual shoreline seems to be covered by foilage and is not visible, ultimately you cannot know, but it could be).
It has probably way too many nodes in wide parts, which suggest a precision that is not “true” (as Richard wrote, the shoreline is not static). Still you shouldn’t select the whole lake and apply a simplify on it, because while some parts (or maybe all) are like the example screenshot, it is also not unlikely that there are parts which people have already improved. This is a way with hundreds of kilometers (in total ~2500km) and you would remove good detail without noticing at first glance. Better select smaller parts that you can overlook and move in smaller steps.
It would have been better, as this is from an import, to massage the data more thoroughly prior to importing it, now we have the burden to deal with it, trying to not loose the work that potentially has been invested.
2 Likes
Simplifying the way is removing precision that was never there in the first place. It’s just not possible to trace a lake boundary that well. There could be offset on the imagery, there is only so much resolution on the imagery, there are trees overhanging the shoreline, the shoreline changes as rocks and trees fall in the water, the person tracing twitched their wrist, and so on. Even if the tool moves the way by 2 or 3m in places, that is well within the error from any of those causes I just listed.
Understand that this over-noded way is actually causing problems, right now. I’m doing QA on boundaries in Quebec and this lake is part of many boundaries. I literally can’t do that work in the region because of this lake. And “buy more RAM” is not a solution.
1 Like
your initial images chosen by yourself show reduction in accuracy, below level achievable by human mapping lake boundary (there is also offset but that is a separate issue)
Have you considered less aggressive simplification? 0.5m would already eliminate doubled nodes that are fake pseudo-detail
4 Likes
there is no obligation to use aerial imagery for mapping, you can use any kind of measurement to acquire data for osm, when we are determining the quality of some mapping, ultimately the comparison has to be made with the real place, not with the limitations of any kind of source (e.g. if these bends from Richard’s screenshot can be found there, it would indicate good mapping, if there isn’t anything particular happening there it would be not so good mapping because two points so close would not make sense, but the fact you cannot see the shoreline on aerial imagery because of the canopy or the resolution of available imagery, are not limitations that determine what is mappable, although they make it so hard that realistically we’ll not do it, as long as we can’t send autonomous surveying drones out for this kind of “scanning”).
The question of precision is not one-dimensional, there can be fidelity of shape (e.g. no edges where there aren’t, angles, etc.) and still a general or local offset / distortion.
A hard limitation we do actually face is the precision of the stored coordinates, but until now it has hardly if ever been a practical limitation (as far as I know).
1 Like
Draw back of partial download is that you loose the closed ring verification, then JOSM complaining the relevant MP download is incomplete
I get that, @SekeRob. I do love JOSM’s relation editor’s “closed loop” feature of multipolygon editing that confirms “yup, this truly is a closed polygon.” However, it isn’t JOSM that “complains” (unless you count this feature displaying a “non-closed loop”), it is JOSM’s Validator plug-in that does. These are either Errors (distinctly bad) or Warnings (can be safely ignored for now, but if you truly know what you’re doing, and this comes with rich experience and long history of OSM editing, fix these if you can).
A strategy I’ve used in this scenario: “JOSM what you must JOSM” (with minimal downloads causing few slowdowns), then, if Errors or Warnings (or even “unclosed polygons” in its relation editor) happen, then spend the network bandwidth / time / slowdown-frustrations to download the entire multipolygon. Sure, you’ll suffer the pain of that (once, at the end, where/when/so it didn’t otherwise hinder your editing), but a quick upload afterwards (after all is OK, of course) and you’re done.
@Graptemys, I read things in your replies, which while they don’t exactly contradict each other, they certainly don’t support each other very well, either. 1) you say “precision that was never there in the first place.” That’s pretty bold, especially as you don’t offer obvious support for how you might know this to be true. 2) you say it’s “just not possible to trace a lake boundary that well.” To which I say, “ditto” (to my first comment): mapping, software, imagery, LIDAR, optics, GPS…all sorts of technologies are constantly improving, and that leads to ever-upward levels of precision. 3) you say “more RAM” is not a solution, yet, as my quick demo proved (I quadrupled my usual allocation for a 60% savings!), actually, yes, it is.
(Your “download more RAM, Rickroll” thing was odd, to say the least)
On the latter point, I don’t want to come across as insensitive like I don’t know that RAM can cost hundreds or even thousands of (fill in your currency unit here). Of course I know this and of course I know that not everybody has “gobs of RAM” (or could) in their JOSM editing machine. But that also says that editing a 200,000 node lake takes a certain “you must be this tall to ride this ride.” And again, thank you for editing OSM, you are on the “OSM data improvement team,” certainly. Assuming there is no noise in the data (which we certainly can NOT do in this case, but let’s say we could), simplifying the data (dumbing it down, throwing away precision) is not the solution, especially as the correct tools to do the job (enough RAM to make editing comfortable) make it possible to do so. But in this case, we’ve noticed there is a certain kind of noise — thanks again, @Richard — so, it’s good we’ll eventually correct that.
The upshot(s)? When editing pretty big data, use sufficiently “pretty big” hardware. That’s no slight, insult or judgement, simply the truth. Also, be careful that you do not “assert into existence” (when they do not exist) two criteria for data precision: one that you say “was never there in the first place” (maybe it was, maybe it wasn’t — I think it’s acknowledged in this thread that these data are noisy) and another that “it’s just not possible” (to, for example, apply to a very large lake shore). OSM doesn’t have (strictly defined) data precision standards. Maybe, especially for imports of giant-sized data, we should. Or at least begin to explore some possible criteria for including or excluding data of a certain level of precision.
Whew. I’d much rather focus on the “light” and apologize if anybody feels some “heat” from all this. My intentions are good, I hope that is clear.
5 Likes
Right, Simon, it IS nice that you can simply “pull in” (to a JOSM edit session) only the part(s) of a gigantic multipolygon that you actually need to be in the buffer while editing. One of my favorite features of JOSM actually (and there are lots, I’m a big fan).
The reason it has a performance hit is simple: the data are huge. I’ve noticed a slowdown in JOSM performance with very large datasets for at least 10 (13?) years. My solution has been to buy hardware (RAM, especially) that accommodates such editing, and tweaking editor settings from my command-line interface accordingly as I have illustrated. And BTW, the near-constant improvement in JOSM, including performance, extensibility, bug fixes and general improvements (it is solid, mature, even awesome software!) has been nothing short of tremendous for the benefit of both JOSM (human) editors and OSM’s downstream data consumers.
1 Like
@stevea Thanks for focusing on the light. It’s good to remember we do all have the same goal of making the quality of OSM data better.
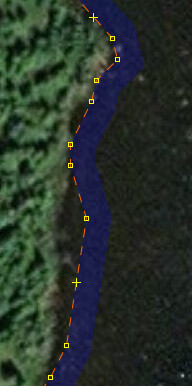
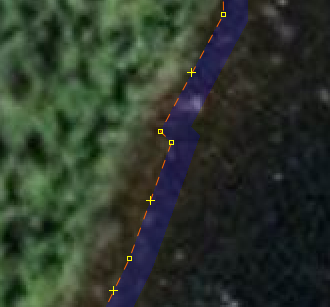
Let’s look at some more screenshots, zoomed in this time. Here’s the inner bend of the same spot as before (but rotated). The three highlighted nodes here are the three that are visible at 2.0m but gone in 2.5m (at the bottom of the small images here). That’s the kind of detail that is being saved at that level. And that bump doesn’t even exist on the lake. The curvature of the bend doesn’t match either. So why keep 25 nodes for that when 10 will do just fine?
2m: Unsimplified:
Unsimplified:
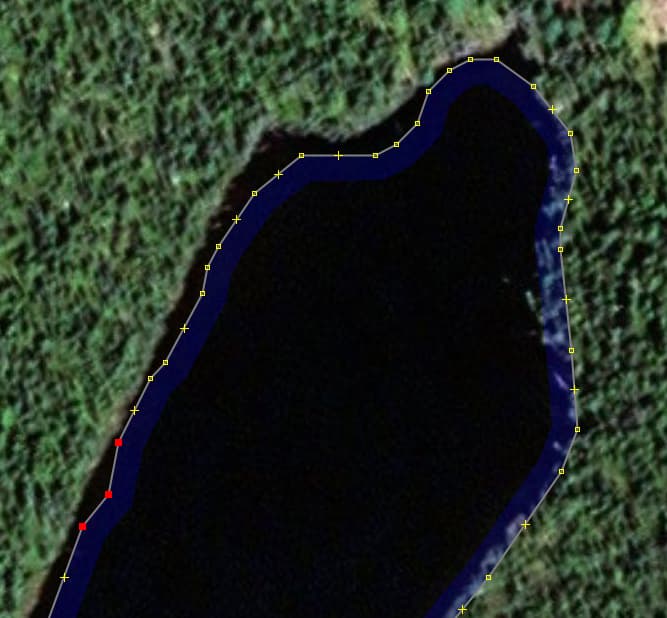
(I’m sorry about all the screenshots and the scrolling you have to do. I encourage you to download and explore the data yourself. This spot is at 50.63052,-73.85312)
Here’s some more spots, chosen this time to show the accuracy of the way (previous places were chosen to show the reduction in nodes). You’ll see that the shape of the way really does not match the shape of the lake to the precision implied by the number of nodes. This was just along one short stretch. There are 1500 miles of this.
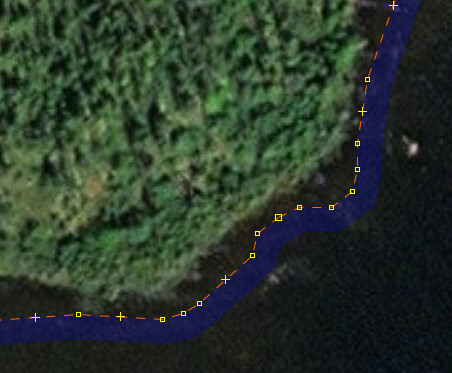
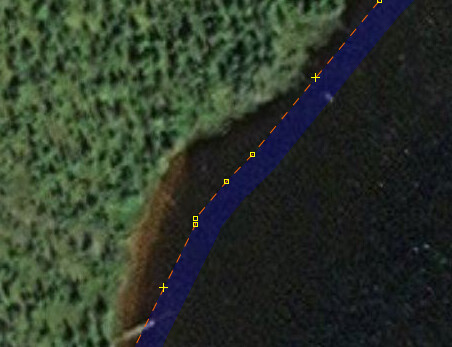
If we could accurately trace lakes at this precision, and maybe we already can today with AI tools or LIDAR, we could have a discussion about whether we should trace more lakes at this precision, remembering that there is a cost to storing and working with so many nodes. However here we are paying that cost and the end result isn’t even accurate.
So yes I understand that big data requires big hardware. My point is that this should not be big data. I’m just trying to reduce the waste caused by all these extra nodes.
2 Likes
Thanks for your participation as a new contributor in Québec, Since you have started by revising administrative limit relations, lake boundaries and names, plus you propose drastic modifications that will affect the quality of data, I invite you to come and discuss with the Québec community on the talk-ca list. As you can see, the north of Québec is often a blank map. I am one of those that spent months and months tracing in detail reservoirs and infrastructures and still able to edit in josm with my 10 years old laptop including this relation 6563858 - Lac Mistassini. And I oppose that you oversimplify the data because you experience problems editing or you think that this is extremely remote and large. There are economic and recreational activies in these areas and they are as important as the others areas of the map.
The maximum error to 0.5 meters or lower seems reasonable to me. But the problem with simplification tools is that they do not take care of curves. A good way to simplify would be to find how to apply on relatively straight lines only. I understand that this is more difficult then « one magical button pressed once ».
Richard, I think that you confuse precision and image alignment. I can assure you that images from Bing and other had constantly evolved in quality, precision and alignment in the last few years. Again this is not an excuse to oversimplify the data in the area. Please dont say like Voltaire that these are only a « few acres of Snow » ![]()
Since you are a relatively new contributor, that good experience is need to work on big relations (I corrected a lot of damaged relations) and that administrative limits work is generally discussed with the community, please come and discuss with the Québec community the modifications you make to boundaries and names.
11 Likes
This smells like import, e.g. changesets 59925786 , 59926570 , 59926713
The source does not give a license, so it is copyrighted data.
1 Like
Hi @PierZen. I have seen your name in the history of many of the objects I’ve been editing. I’m glad you saw this.
I would love to discuss this and many other things with the community. Has there been any talk of making a Canada category on this forum? I would find that much easier than mailing lists.
2 Likes
There was no discussions about this and dont forget that Québec has its own reality and « nous parlons français ».
Yes, they do.
No amount of “flattening” these data will make them anything BUT big data. These are big data, that’s all there is to it. It’s a question of HOW big. When “many editing environments” are crippled, it is good of us to examine how we do things, as it’s likely we can find an agreeable middle. Or one good enough for today and with lessons on how to make a better one for our future.
Yes, again, it’s a question of HOW big. That’s under discussion, and has been, and numbers (of 0.5 or 2.0 meter resolution or a number of methods we might use to specify such precision…) are being discussed. Which tools / platforms / plugins / algorithms-approaches we might choose, we’re sort of warming up to that. (Starting with “straight stretches” has worked for me in the past as I attempt to do such “edge simplification,” but again, this is careful, tedious work). Then, there is the “how” someone (or a team), or a process we might specify and document we’ll use going forward, does this. As in “here’s what we did with a big lake in Canada and the community liked it after we discussed how and what we’re gonna do and then we did it.” We can get there, and I like how we progress towards.
Edit: Clarified, fixed some minor typos.
Replying to myself. OK, OSM, we’re chewing this gum, let’s blow a bubble.
It seems clear there is a “shortly-described algorithmic approach” to (both, it turns out) simplifying and improving our “lake with 200,000 nodes.” It goes something like “segmented into ways of ≤1899 nodes…with 1.5 meter resolution otherwise.” The … is others sketching in what the toolchain is.
Doable, and a good win for OSM, actually. Minor effort, major learning capsule to open up again in the future. A two-fer: simplify AND improve. To our exact specifications as “as good as we can” (for today).
We have the breadcrumbs. We have the technology. We have the community.