I’d suggest repeating the names of fields from the GTFS standard:
route_id
route_short_name may be mapped to ‘ref’ on OSM
trip_id
stop_id
agency_id
…
I’d also suggest adding a section: “Pros/Cons on utilizing them extensively in route_master/route relations” or something like that. Just mentioning that route_ids, trip_ids aren’t stable/fixed/reliable over time for some, not all GTFS sources.
Or should I mention this in the corresponding “discussion” page?
This looks like a rather complex proposal and I admit I have not understood it in full. Can you say in a few words in how far this will affect mappers not interested in GTFS at all?
Will there be additional (i.e. in addition to existing railway route) relations that contain individual track segments so that someone who, say, splits a railway track to add a speed limit will get an alert about having modified a GTFS relation? Will someone editing a train stop have to deal with GTFS objects/relations? Are there any situations where someone making a GTFS-unrelated edit will suddenly have to upload a modified relation with a four-digit number of members? – Those are the kinds of questions that I ask when deciding whether to object to a proposal.
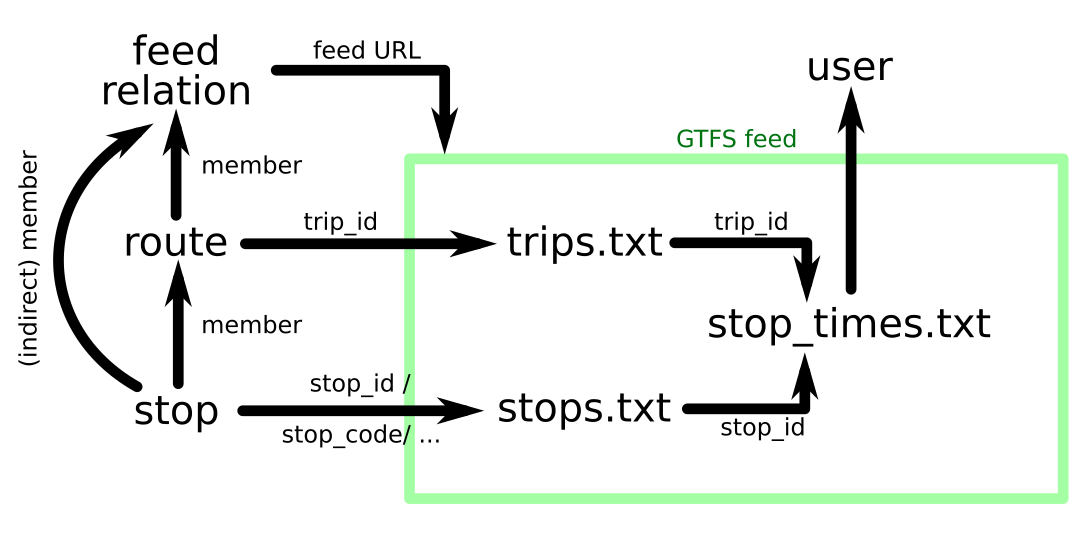
No. The railway route relation is part of the GTFS feed relation, but the track segments are not. Even if you consider cascading membership, the idea is that you look at the type of object before including it in the extended relation. Since a track segment is not one of the listed types that can correspond with GTFS objects, it is not included in the extended relation.
Not if they don’t want to.
Adding a train stop / platform to a route or stop_area_group that is already part of the (extended) GTFS feed relation will indirectly add it to the extended GTFS feed relation.
Another mapper (or program) could then come along and add the appropriate gtfs:stop_id.
This issue was pointed out in the RFC, the cascading membership solves this.
Essentially:
if a network is part of the relation, we don’t need to include any routes in that network
if a route is part of the relation, we don’t need to include any stops on that route
if a stop area group is part of the relation, we don’t need to include any platforms in that stop area
Deleting an object that was a direct member? or does the API handle that automatically?
I want as much as possible to keep editing the PTv2 objects and adding the GTFS references on top to be separate. Both to not burden PT mappers even further - it is already difficult enough. And to allow automated tools to keep the references up-to-date in a way that does not touch human mapping - to ease the process of requesting approval for automated edits.
I would suggest aborting the voting at this point in time, there hasn’t been remotely enough discussion for a proposal with so much potential impact, and even simple things like a couple of actual examples of what the proposal would be like on real data are missing. This doesn’t mean that I consider the proposal in its core a bad idea, it is just very premature to go in to voting.
With a different hat on: the proposal needs a discussion of what if any editor support is needed, particularly wrt route data (that is already an issue with PT transport routes as it is now).
This might just be a language issue, but I suspect what you actually want to say is “we don’t need to include any routes in that network” and similar for the other two points.
From my end this proposal looks very technique oriented. It doesn’t give me clear use case, I assume because all PT experts know what it will enable for the end user using a map application.
I get that you want an OSM based application to access external PT timetables. I don’t get what event will trigger this access.
In Google Maps, I get PT information 1. when I click or tap a bus stop. 2. when I mark a destination and ask for routing, with PT option. It will then find stops nearby and from there route from stop to stop, including transfers. Is that the idea? Then PT stops are the main interface to the functionality. The access information for GTFS then MUST be tied to the stops.
You do not want to overload stops with all the timetable ID’s of all PT lines. OSM records are basically fit for only one item per key. So you want to use a connecting relation which should then include all the stops (and possibly other PTNA-initiating items) it handles.
So from the stop an application or router can find all the GTFS-relations it appears in, then display them or list them with just the gtfs stub information, refer the user to a different system, or get information on the fly for use within the application or router.
Correct. As an aside: routes can also be the access points (like when you ask for all the departure times along a route). So everything mentioned about stops also holds for routes.
Indeed, the stops are the main interface. To find the timetables we need two things: feed URL and stop id in the feed. We could just tag these on the bus stops, but that means the feed URL is the same for thousands of stops. The feed relation ensures there is a single place to update if anything changes about the feed. An additional benefit is that we can find other stops managed by the same feed.
I think you use the abbreviation PTNA here for “Public Transport NAvigation”.
PTNA (Public Transport Network Analysis) is a tool by ToniE to look at PTv2 (as QA) and GTFS (to ease mapping public transport in OSM).
GTFS feed information is not directly interesting for a user. There is no use case to display GTFS stub information. Think of an GTFS feed as an API. The data you can request from the API is interesting to a user, not information about the API itself.
To illustrate the whole process, how you would find the times that a bus route stops at a particular stop.
Right! I think I’m catching on. This probably is well known context for adepts, but not clear to the innocent mapper as I am.
If this use case/context is provided in the proposal as you just explained it to me, I think the technical issues will be much clearer to many more people. In the end, I think, you want it to be generally understandable documentation of the mapping and tagging. Hell, I might even vote!
Thanks for your effort. I would prefer to have this proposal split into at least two, though.
I really like the first two items of harmonizing the tags and the last item about different stop_ids for one stop per feed/source. For the latter, please, do not forget Key:ref:IFOPT - OpenStreetMap Wiki which is used in Europe and maybe think about adapting it to all GTFS ids (route_id, shape_id, trip_id, trip_id:sample). DE-BW-VAG and DE-BW-VAG-NVBW is an example of two feeds with different ids for the identical routes/trips.
What I do not like and which would lead to vote against the proposal at its current version is the third item, the feed relation. This new type would be just a collection and simply its possible huge number of members speaks against it. Additionally, inheriting tags from relations does not work and splitting related tags across several objects is a bad idea. If the feed changes, you’d still have to check every member and adjust the ids of every member correspondingly. For bigger feeds this would be impossible to do in one step and even for small feeds with only 20 or 30 lines it is quite some work to check every trip of every route at once. Last but not least, overpass can easily find you every object with a certain gtfs:feed value that there is no need for this collection as a relation.
It represents something itself, namely the feed.
To put the properties of the feed, like its URL, on all public transport objects seems like a bad idea to me. Do you have any suggestion where to put this URL (preferable only a single copy) and other properties of the feed?
This was brought up in RFC, and I added cascading membership to solve this.
This means that not only direct children, but all descendants are considered part of the relation.
For example: If we only include OV-concessies Nederland, we get 1883 route_masters, 4026 routes and 57661 stops for free. These do not need to be direct members anymore. What remains are the stations (because they are not included in routes) and disused stops (which might not even be present in the feed).
I do not consider tagging feed properties on the feed relation to be inheritance, but I see why you might call it that. Do you have any reasons you believe this to be problematic / examples where this has gone wrong?
Each object only gets the tags relevant for that object. Each route only gets the information to find that route in the feed. Each stop only gets the information to find that stop in the feed. And the feed relation only gets the properties of the feed itself.
That is why I advice to do an analysis before starting to tag id’s. I think that for most feeds a suitable combination of tags can be found that are stable. Furthermore - a program could check for differences so it requires less manual labor than this sentence suggests.
In my propsal, gtfs:feed is only present on the relation to define its feed code.
It is not put on the objects since it is not a property for those objects.
So instead you would need to find all objects with gtfs:*:(feed_code)=*.
This can be done in overpass, but requires regex matching - though still easier than traversing relations.
However, then it will not find any objects that do not have the feed code in the key.
Thus, without the relation the feed code suffix is always required.
In the current proposal it is only strongly encouraged.
The feed URL points to the zip file.
So for OVApi: https://gtfs.ovapi.nl/nl/gtfs-nl.zip
The reason the iterated lookup is needed is because ID’s are not stable enough for some feeds.
For a feed where the ID is stable, you could directly use gtfs:stop_id / gtfs:route_id in stop_times.txt and skip finding the right rows in the stops / routes table.
If it is not supposed to be a collection, this sounds more like a boundary to me (boundary=gtfs_feed), similar to boundary=public_transport.
If the stop_id, route_id, … are taken from a gtfs feed it looks perfectly right for me to add gtfs:feed=* (and gtfs:url=* if needed) to the object. It is similar to network:wikidata=*.
Why do you think this would be a bad idea?
Cascading makes it even worse as you would have to look at several layers of parents. Inheriting tags from parents, grandparents, … is not supported by any editor software, I know of, or the server’s object page. It would mean to first make sure all these parent relations are loaded only to find two tags which could have been added to the object directly. That adds quite some unneeded traffic to the server, only to check one single route. Yet another problem would be if the tag with different values is present at different levels.
See above. Additionally, this reminds me of the discussions of type=associatedStreet (abandoned in Germany), type=street or type=multistring. All concepts which could be used to save repeating of some tags but do not reliably work that way.
Well each route and each stop needs gtfs:feed and gtfs:release_date. So we end up with less than a handful of additional tags but a complex concept of several levels of relations? Are these additional tags that important and useful?
GTFS and stable ids is a mismatch on its own and one, if not even the biggest, problem of current standard. But that is a different story.
All the support needs to be implemented in editor software. I have coded really little support in Rules/PublicTransportGtfs – JOSM and it would be nice if you could come up at least with a concepts how these checks should work.
Well current usage in my area tells a different story. gtfs:feed is present on each objects along side the ids. The feed code suffix is only needed if the object is in more than one feed with conflicting ids.
Sorry, I do not understand why we would need these complex relations. What do you try to solve besides adding two or three less tags to the objects.
You are starting to convince me. The proposal would be a lot simpler without the feed relation.
When I originally made the proposal there were better reasons for the feed relation.
But with how the proposal has changed, this is no longer the case.
I still don’t like the idea of tagging the URL on all objects - if the URL changes it needs to be fixed on tens of thousands of objects - among which relations (route/route_master) which are traditionally hard to edit.
I think a wiki page that lists all feeds that are represented in OSM and their feed codes is a good idea. This allows mappers to find which codes are already in use.
We could use this as the place to store the feed URL.
We need to make sure that this page is machine-readable. I think we can achieve this by making a template for GTFS feeds and using that for each feed.
The only downside of the wiki approach is that it is not part of an OSM extract.
It would require to query the wiki - which is not really designed for that purpose.
(I think a suggestion to cache these results would be proper)