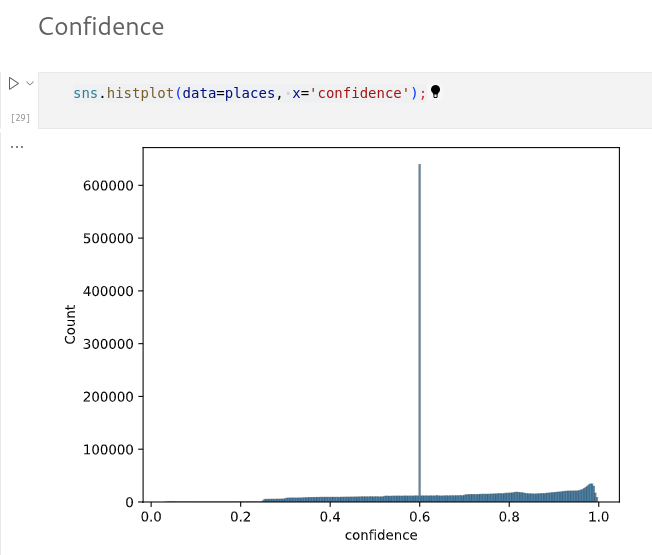
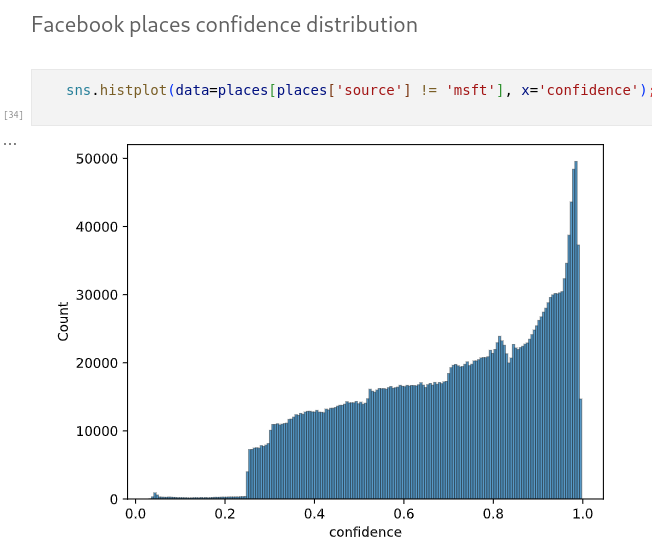
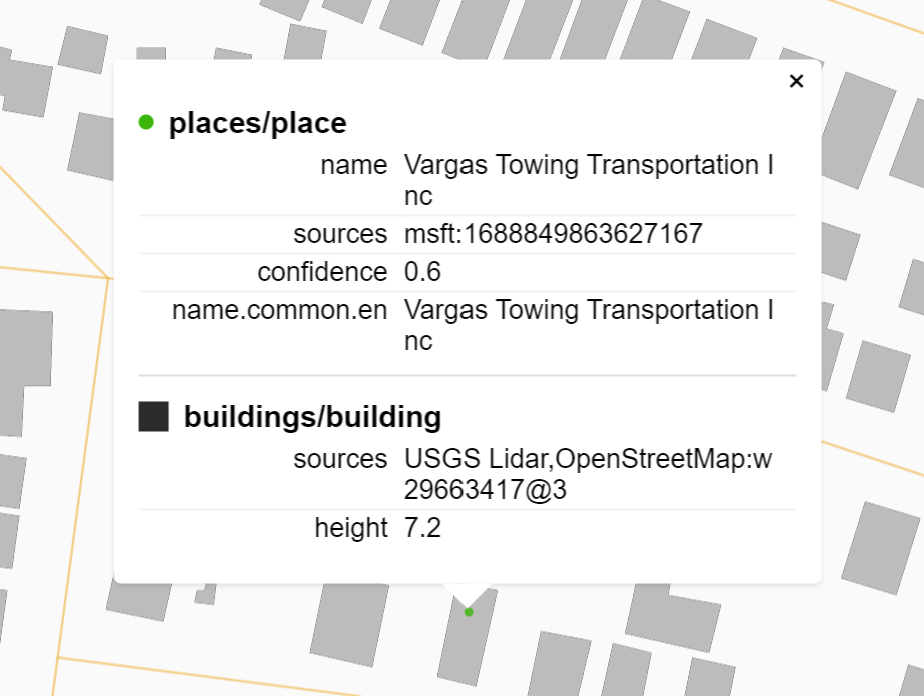
Hi, I’ve updated my visualization to include the confidence score on click, as well as a slider to filter the visualization by minimum confidence level:
They have Rocky Mountain National Park located in Loveland Colorado, about 20 miles from the nearest part of the actual park. They have Roosevelt National Park also located in Loveland. There is no Roosevelt National Park. There is a Theodore Roosevelt National Park in North Dakota, over 500 road miles away. There is also a Roosevelt National Forest, but it’s nearest part is about five miles away.
Upping the confidence revealed some really big bloopers that previously were buried in all the other noise. For example there’s a node with the name of our municipality with confidence 0.82 that is a) located in a neighbouring municipality, and b) classified as a mountain (both is nonsense).
I had a look at some POIs in rural Austria. Mostly businesses and restaurants, pretty good actually. The only landmark feature (confidence 0.96) was about 1 km off (so they haven’t copied from us ).
Similar picture in Vienna. Lots of shops, but every now and then a POI with confidence > 0.95 is off by a few 100 meters.
Quite a few duplicate landmarks, some of them wildly misplaced and strangely named. Don’t use for hiking!
Nothing that couldn’t be fixed, I guess. But they certainly have work to do.
Note if you filter by confidence that all points with source = msft have the same confidence of 0.6. So if you filter for confidence > 0.6 you ignore all of those.
Hello! I also made a visualization using planetiler of all of the layers in the July Overture dump (except transportation connectors) if you want to explore:
It’s kind of interesting how they cite OpenStreetMap as the source there. Not good or bad, just interesting. Hopefully a less raw (is that even the right word?) version has or will have a link to the site. If not also the tag line about how data from OpenStreetMap comes from a global community of mappers or whatever it is. If you have to click on the POI to find the source and there’s no way to find out more about it from there that’s kind of muh though. Not to mention it also leaves out the licensing information, which seems important (or conversely maybe that’s just how Mike Barry decided to implement it ).
The original source data looks like: [{"dataset": "USGS Lidar"}, {"dataset": "OpenStreetMap", "recordId": "w29663417@3"}] and I process it into a string using this code. The record ID appears to be conveyed as a string that looks like "{w,n,r}<id>@<version>". Licensing information is conveyed at the dataset level which I show in the bottom-right corner.
Interesting analysis from @wille on the places data quality:
Key Findings:
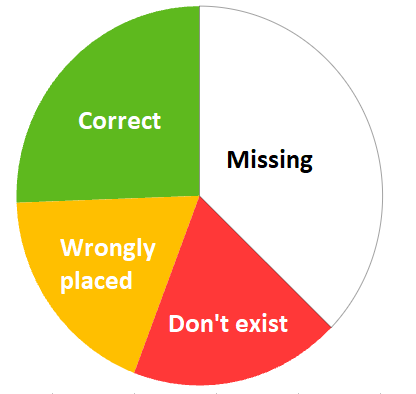
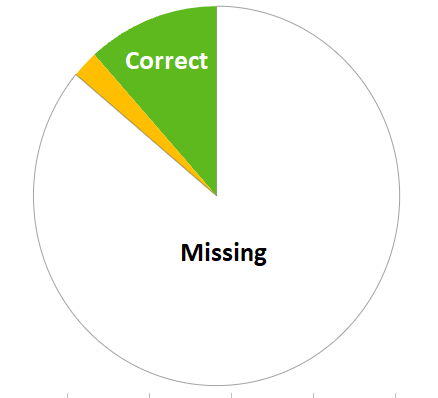
General Accuracy: In a sample analysis of 308 places in Salvador de Bahia, Brazil, 63% of the places were found to be correct, irrespective of their confidence score.
Confidence Score Correlation: The accuracy of the dataset increases with the confidence score. For items with a confidence score of 0.6 or higher, the accuracy rate was 81.2%. It further increased to 95% for places with a confidence score of 0.9 or higher.
Category Issues: The categorization of places needs improvement. For example, similar categories like ‘cafe’ and ‘cafeteria’ or ‘psychologist’ and ‘psychotherapist’ exist, making it confusing.
Data Quality: The main issues in the dataset are inaccurate locations and outdated places. For correct places, “small deviation” in location was the most common issue, while for incorrect places, being “outdated” was the primary issue.
The article concludes that the Overture Places dataset can be highly useful when filtered by a confidence score of 0.6 or higher, although improvements in categorization and data quality are needed.
Having seen various similar comparisons from other people about their places, this first POIs dataset release feels like “it’s something but it’s not that great”.
For my area, about half of the POIs exist currently. The other half contains POIs that either stopped existing years ago or even never existed (imaginary names). And it felt like an import of online store catalogs which already contained incorrect info, which I have seen unfortunately been imported in other maps.
And that’s what I’m afraid about this dataset. People coming to OSM to import whatever doesn’t exist from the dataset.
Main gist: They need the linear referencing system to be able to reliably conflate sources
“To make the transportation layer we take open data, which is mostly OpenStreetMap (OSM) at this point, and manipulate it to meet Overture’s requirements,” Clarysse explains.
“We quality check the OSM data to make sure it’s consistent according to Overture’s specification, we segment the road network using a consistent logic for the whole world, and then remap all the relevant road attributes that we know about from the open data to the new map,” he adds.
It’s easy to see how quickly this could get out of hand, when there’s a whole world of people and organizations adding unique data to a map.
“At some point, it just doesn’t scale well anymore. If everyone using the map adds things on top that require their own sectioning or segmenting, then it will not scale, and everyone would be fighting over the splitting, and how the roads are segmented,” Clarysse says.
“We have started with roads, but as we take data from open data sources, we are working to add pedestrian walkways in the upcoming releases. This will further increase the Overture transportation layer’s completeness, which is a big focus for us going forward.”
I would hope that all now realize that the cooperation and “not a OSM competitor” statements were worth exactly what every knowledgable of US-corporate speak person said they were: nothing.