Lots of good points raised in this thread. It seems to me that there are some situations where a standard semicolon delimiter offers a nice amount of flexibility to a data consumer. If I’m making a map, the unordered list Bozen;Bolzano tells me that two different names are used locally and the tags name:de=Bozen & name:it=Bolzano tell me which language each name is associated with. From this information I can generate a variety of different label styles depending on the purpose of the map. Some examples:

This works because each name is distinct (even if similar) so displaying both does not feel redundant. In this case, structuring the data for flexibility seems good to me. However, this should only be for cases where both names truly are equally important locally. If the local community considers one primary and the other secondary, putting one in name and the other in alt_name makes that clear and should be preferred.
The cases where some words are redundant between the multiple names are less clear to me. While Carabinieri Bozen;Carabinieri Bolzano would seem perfectly accurate, the label style examples above would look much more cluttered with the word Carabinieri repeated. It certainly would be nice to be able to construct “Carabinieri Bozen / Bolzano” or “Carabinieri Bozen–Bolzano” from the list of both full names.
The Canadian Province of New Brunswick is bilingual and officially goes by it’s French name, Nouveau Brunswick, as well. A map label of “New / Nouveau-Brunswick” wouldn’t be wrong, but in this case “New Brunswick – Nouveau-Brunswick” seems preferable to me. Probably because Brunswick by itself refers to a different place.
Ottowa, Canada signs its streets in French and English, but the unique part of the name is the same in both languages (and sometimes the prefix and suffix words are too). For example “rue Percy St.” which expands to “rue Percy Street” or “av. Powell Ave.” which expands to “avenue Powell Avenue”. It looks like Ottowa mappers have chosen to put the English variant in the name tag, but lets imagine they used a semicolon delimited list. Here are some examples of how these two names might be displayed on a map:
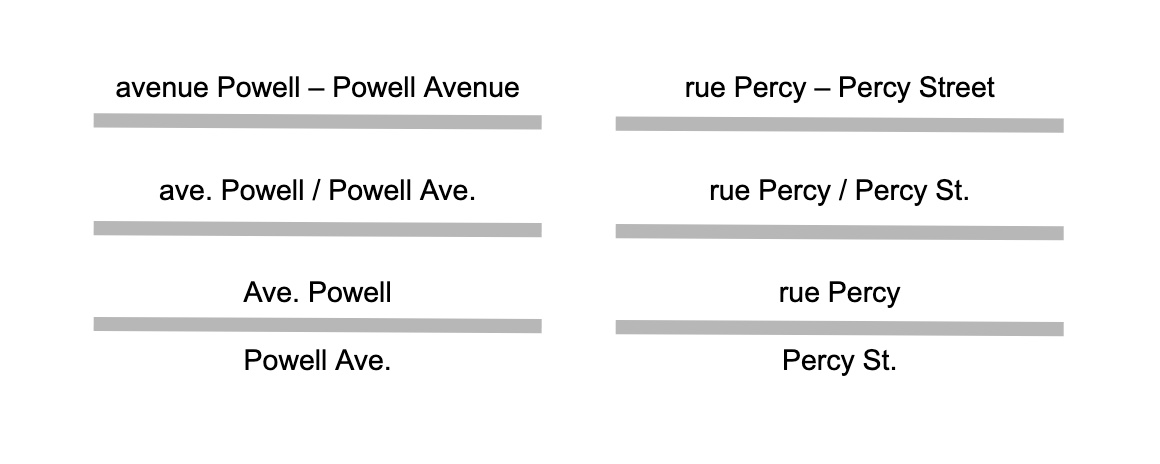
That’s quite a lot of redundancy just to show that the French word for street is rue, but it is a reasonable representation of the signage on the ground. Matching the signage exactly with the format “rue Percy St.” and “av. Powell Ave.” would be the most space efficient option, though perhaps not universally preferred.
An automated rule set might behave a bit differently for each of these examples:
-
Carabinieri Bozen;Carabinieri Bolzano→ “Carabinieri Bozen / Bolzano” -
New Brunswick;Nouveau-Brunswick→ “New Brunswick – Nouveau-Brunswick” -
rue Percy;Percy Street→ “rue Percy St.”
There are probably other semi-redundant multi-name situations where a different output would be optimal. An automated rule set like this would be difficult to get right, though it is an interesting problem to think about. Simply formatting these type of names exactly as one thinks they ought to be printed on a map certainly is enticing, but it limits what map makers are able to do with the data. I think shifting more delimited names to use the standard semicolon would be a net positive in the long run. For more complex redundant word cases, perhaps it doesn’t make sense currently, but for the simple cases the benefit seems quite clear to me.