I pulled down an overpass query today of all names with a semi-colon in order to do some cursory analysis.
This is my overpass query:
[out:csv(::type,::id,::user,wikidata,name,place,boundary,highway,amenity)][timeout:2500];
nwr[name~";"];
out;
Below is a link to the raw data. I’ve included some convenient pivot tables showing primary tag prevalence in separate tabs. This spreadsheet is in LibreOffice Calc (.ods) format.
In summary, this is used in:
- 489
place=* objects
- 38
boundary=* objects
- 13,401
highway=* objects, of which 761 are highway=motorway_junction
- 285
amenity=* objects
Those were just the top-level tags that I checked. There are still another 17K or so objects that are some other top-level tag, such as power features and landuse/land cover areas.
Examples
Below is a gallery of screen grabs from osm-carto showing rendered semi-colons, just to give a flavor of the diversity of usages:
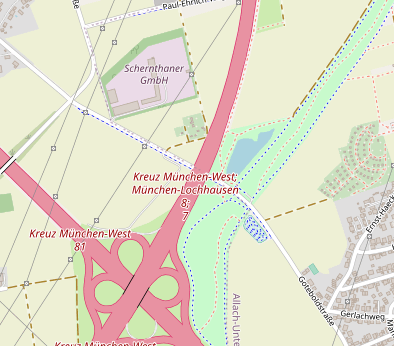
A highway=motorway_junction near Munich, Germany:
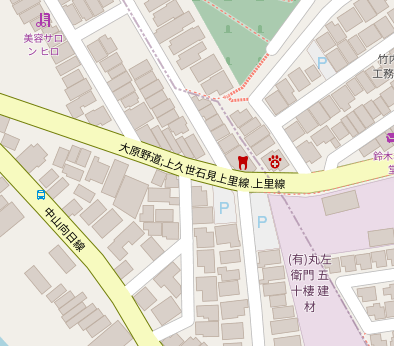
A highway=secondary near Kyoto, Japan:
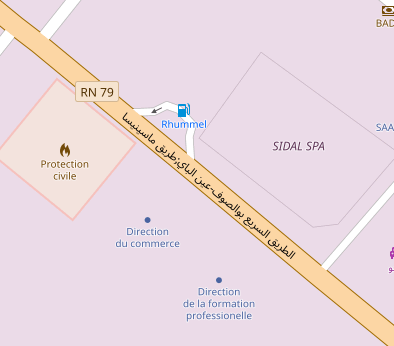
A highway=primary near Constantine, Algeria. The semi-colon is difficult to spot amongst the Arabic text, but it’s there!
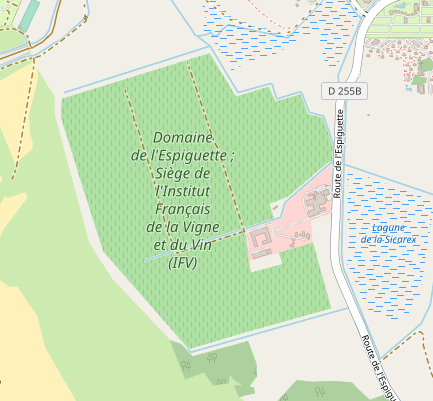
A landuse=vineyard near Marseille, France.
An amenity=place_of_worship in Cincinatti, Ohio, USA:
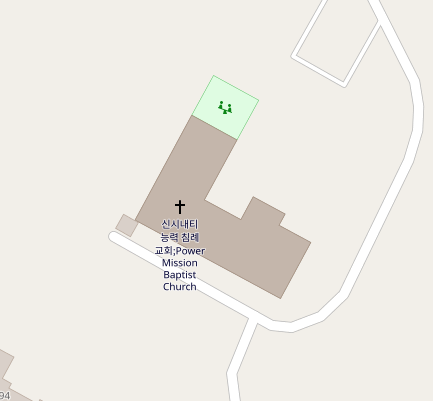
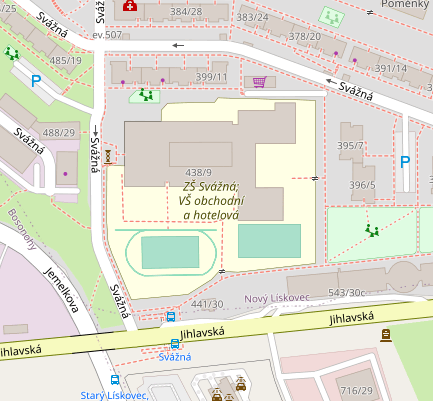
An amenity=school near Brno, Czechia:




{kind=link}
{kind=link}