Migrating Tasking Manager: From Flask to FastAPI and psycopg2 to asyncpg
In the ever-evolving world of software development, performance and maintainability are crucial. Tasking Manager, an open-source project, is no exception. As part of our continuous efforts to improve our codebase and address the technical debt, we recently undertook a significant migration: transitioning from Flask to FastAPI for our web framework and from psycopg to asyncpg for our database interactions. This post will walk you through our journey, the rationale behind these changes, and the benefits we anticipate.
Why FastAPI and asyncpg?
FastAPI:
- Performance
FastAPI is built on top of Starlette for the web parts and Pydantic for the data parts, making it incredibly fast and efficient. It leverages asynchronous programming using Python’s async and await syntax, allowing for non-blocking operations. This means FastAPI can handle many requests simultaneously, resulting in high performance, especially in I/O-bound operations.
- Ease of Use
FastAPI simplifies API development by automatically generating interactive API documentation using Swagger UI and ReDoc. This feature is invaluable for developers as it provides a visual interface to explore and test API endpoints, making both development and API consumption easier and more intuitive.
- Modern Features
FastAPI embraces modern Python features, including type hints. Type hints improve code readability by clearly specifying the expected types of function arguments and return values. They also reduce errors by enabling automatic validation and providing better support for IDEs and type checkers.
asyncpg:
- Asynchronous Support
asyncpg is designed specifically for asynchronous programming. It enables the handling of multiple database queries concurrently, making it possible to perform several operations at once without blocking the execution of the program. This concurrent handling significantly improves the throughput of database interactions.
- Performance
asyncpg is highly optimized and often outperforms other PostgreSQL drivers. Its focus on efficiency and speed makes it a top choice for applications that require fast, reliable database operations. The driver takes advantage of asynchronous programming to minimize latency and maximize performance.
The chart below shows the geometric mean of benchmarks obtained with PostgreSQL client driver benchmarking toolbench in June 2023.
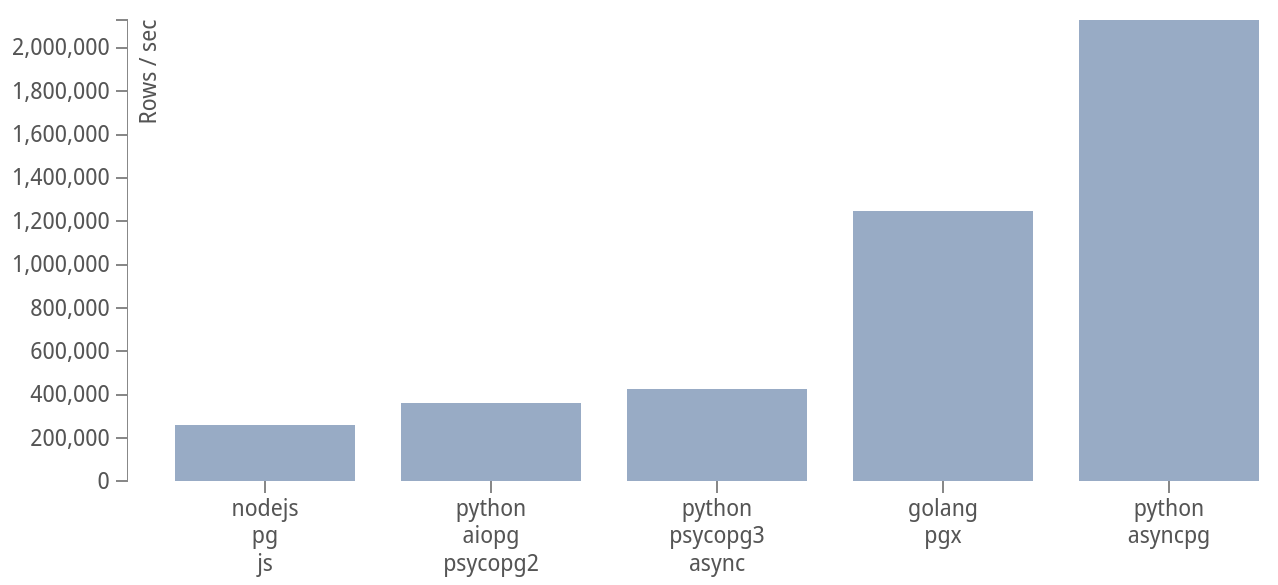
To understand synchronous and asynchronous execution better, we first need to distinguish between subroutines and co-routines. A subroutine is a block of code that can be invoked as needed, transferring control of the program to it and returning to the main program once its task is complete. Subroutines run until they finish and cannot be paused and resumed.
Conversely, a co-routine is a special type of function that allows its execution to be paused and resumed, maintaining its state between pauses. This capability makes co-routines ideal for tasks that involve waiting, such as I/O operations, database calls, and HTTP requests. The term “co-routine” combines “co” (together) and “routine,” suggesting routines that can run cooperatively.
In a typical single-threaded application, all code and subroutines run sequentially, which is simple but can be inefficient. To optimize resource utilization, we use concurrency and parallelism. Concurrency allows the start and stop times of multiple co-routines to overlap, while parallelism enables different threads to execute simultaneously.
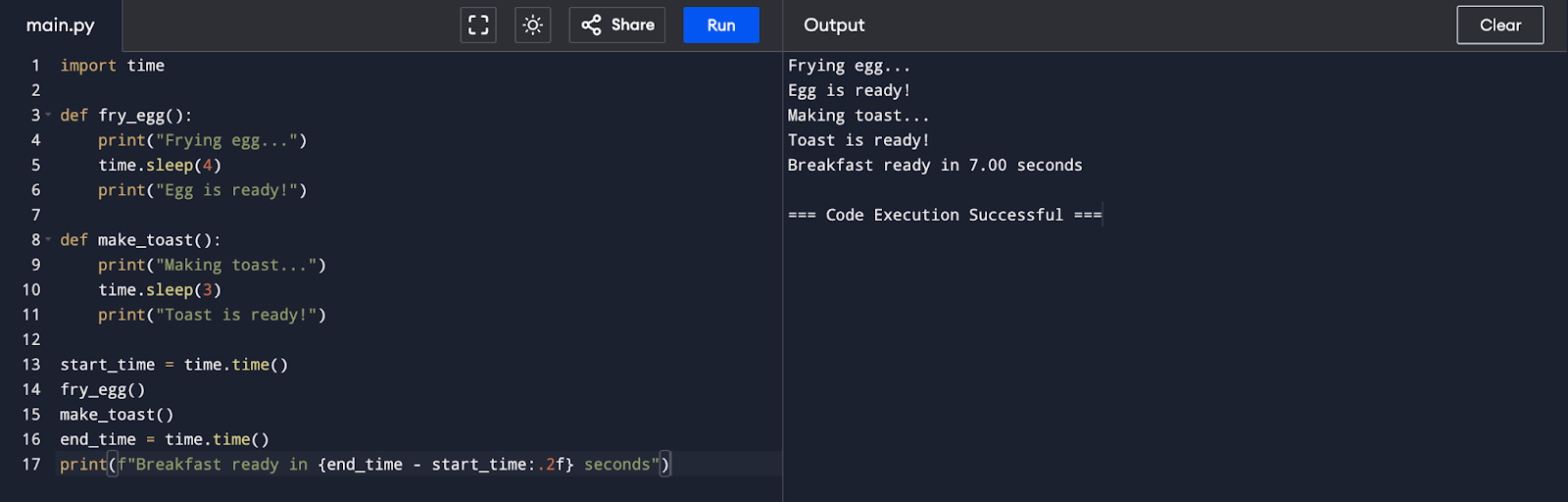
Now, let’s see how to implement concurrency in Python using the async and await keywords and the asyncio module. We’ll create two functions: fry_egg and make_toast. The fry_egg function will use the sleep function to simulate a 4-second task, while make_toast will simulate a 3-second task. Running these functions synchronously would take 7 seconds, but there’s no need to wait for the egg to finish frying before starting to make the toast. We can make this process more efficient using co-routines.
Synchronous Code:
Asynchronous Code:
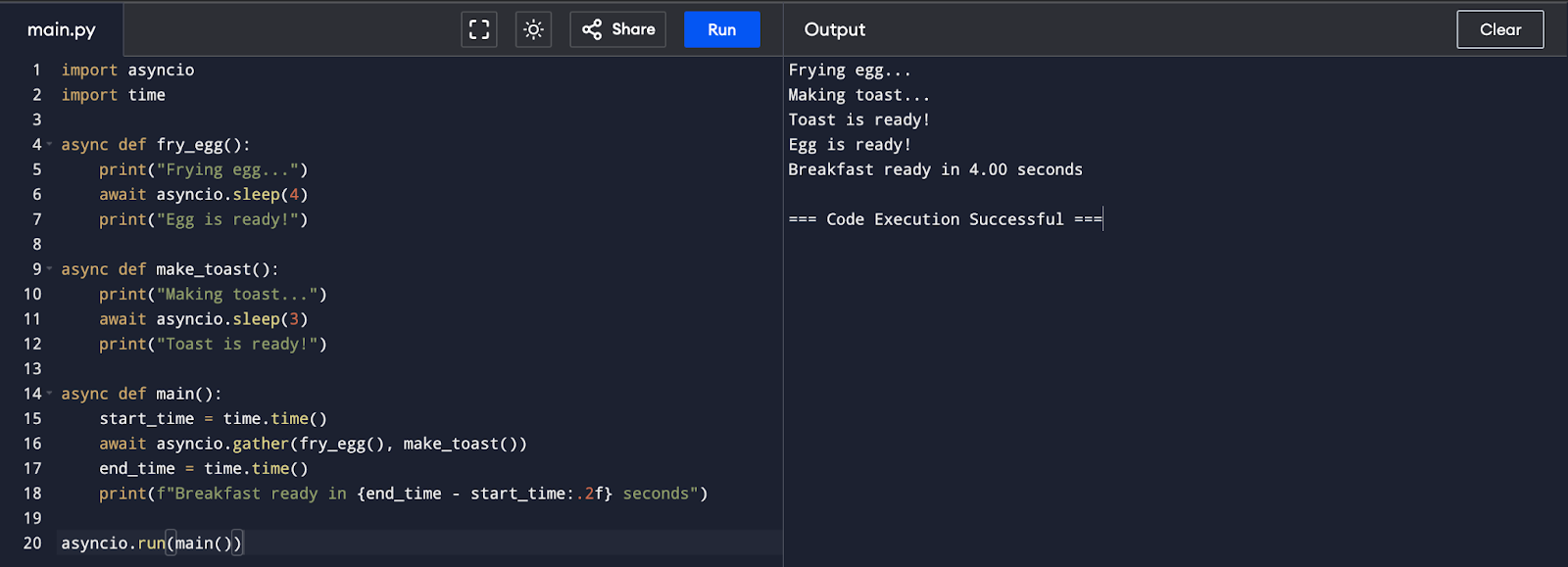
By using asyncio, the total time is reduced to 4 seconds, showcasing the efficiency of asynchronous programming. This demonstrates how co-routines can help manage tasks that can run concurrently, making better use of computing resources and reducing overall execution time.
The Migration Process
WWe began our migration by focusing on the most critical API: the endpoint for getting projects. This API was essential as it interacted with many parts of the application. Successfully migrating this endpoint gave us confidence and a deeper understanding of how to proceed with the rest of the project.
Next, we decided to migrate the codebase module by module. We compiled a comprehensive list of all the APIs that needed migration and documented them by module. This structured approach ensured that we could track progress and tackle each part of the application systematically.
We started with the campaigns and organizations modules, as these were less complex and provided a good testing ground for our new asynchronous setup. Completing these modules allowed us to identify and resolve potential issues early on, minimizing complications when moving on to more complex APIs.
Currently, we have completed the campaigns and organizations modules, including all the CRUD operations and related functionalities. This approach ensured that we covered various aspects of asynchronous programming and avoided common pitfalls.
The teams module and parts of the project module are also in progress. Specifically, project list and retrieve functionalities have been successfully migrated, and work on other parts of the project module is ongoing. This incremental and modular approach has allowed us to manage the complexity of the migration effectively and ensure each part is thoroughly tested before moving on.
To align with the architectural patterns encouraged by FastAPI, we are also exploring refactors like incorporating Pydantic field validators to streamline variable assembly and also investigating libraries like ‘databases’ to effectively utilize SQLAlchemy Core expressions. These efforts aim to make the codebase more manageable and to ensure a robust and maintainable application structure.
Challenges
- Learning Curve: Transitioning to asynchronous programming can be challenging for developers unfamiliar with the concept.
- Refactoring Code: Migrating from Flask to FastAPI and shifting from synchronous to asynchronous database interactions requires substantial refactoring. This includes updating each CRUD function and library to ensure compatibility with the async framework. Debugging asynchronous code introduces additional challenges due to concurrency and potential race conditions, and proper error handling and propagation must be maintained. Additionally, API endpoint migration involves rewriting Flask routes to FastAPI endpoints while ensuring that all functionalities are preserved and that clients consuming the API are informed of any significant changes. Concurrency management requires careful handling of concurrent requests and shared state in an asynchronous environment. Finally, updating deployment configurations and ensuring Docker containers are correctly set up for FastAPI and asyncpg, including environment variables and volume mounting, are crucial for a smooth transition.
- Libraries and Third-Party Integration: Deciding whether to use libraries like ‘databases’ or async SQLAlchemy involves evaluating their suitability for your specific needs and getting familiar with their functionalities. This decision impacts how non-blocking database operations are managed in your application. Additionally, integrating these libraries with third-party services can be challenging, as not all Flask extensions or services have direct equivalents for FastAPI and asyncpg. This may require finding suitable alternatives, writing custom solutions, or ensuring that existing integrations function correctly with the new asynchronous framework.
- Lazy and Eager Loading: Properly managing lazy and eager loading of relationships can be challenging in an asynchronous environment. In traditional synchronous frameworks like Flask with SQLAlchemy, you may have well-established patterns for loading related data. However, in FastAPI with asyncpg, you need to adapt these patterns to work efficiently with async database operations. This involves ensuring that related data is loaded appropriately without causing performance issues or excessive database queries, which may require rethinking how you handle relationships and optimize queries in the new setup.
- Codebase Refactoring: Organizing the codebase to fit the architectural patterns encouraged by FastAPI, which is different from those used in Flask.
Migrating Tasking Manager from Flask to FastAPI and from psycopg2 to asyncpg is an ongoing journey. While we are still in the process, we are optimistic about the potential improvements in performance and scalability. For any open-source projects or applications looking to enhance performance and scalability, adopting FastAPI and asyncpg is a promising step. We hope our experience so far provides valuable insights for the community and encourages others to explore these tools.
Feel free to contribute to Tasking Manager or reach out with any suggestions.Your feedback, suggestions, and collaboration have been instrumental in driving this project forward. Here’s to continued innovation and improvement in the world of open-source software.