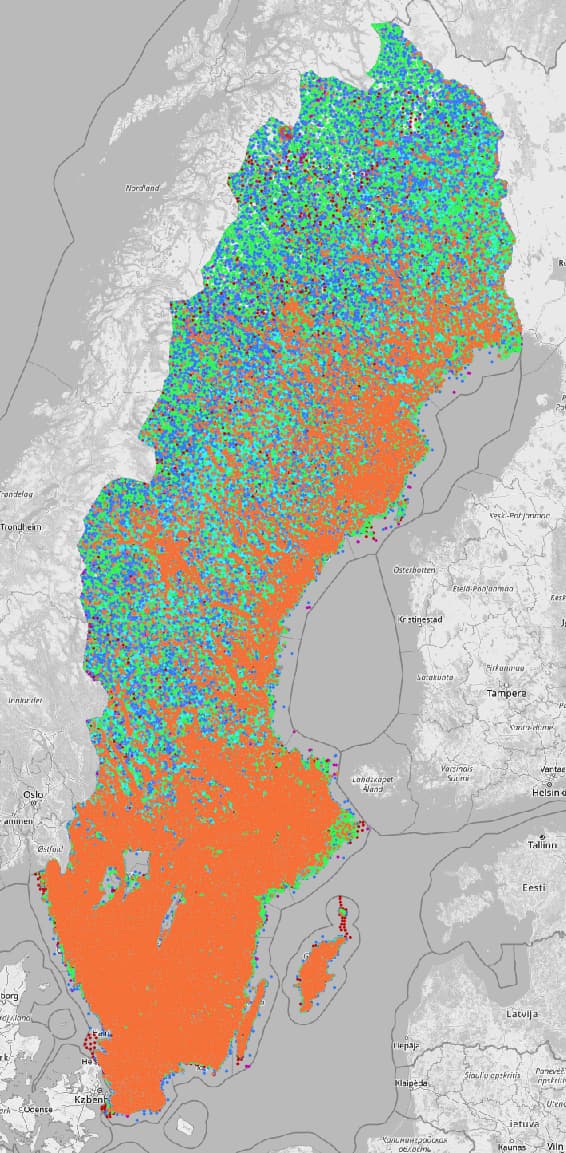
Jeg har lastet ned Ortnamn fra Lantmäteriet etter at datasettet nå ble gjort tilgjengelig. Jeg har kjørt et skript som tagger med riktig name:xxx=* og har lagret som en geojson-fil per kommune + en samlet fil for hele Sverige. Filene kan leses direkte inn i JOSM. Her er filene:
Der det finnes navn på andre språk enn svensk er disse taggene brukt:
name:sv - Svenska
name:fit - Meänkieli (tornedalsfinska)
name:fi - Finska
name:se - Nordsamiska
name:smj - Lulesamiska
name:sju - Umesamiska
name:sma - Sydsamiska
Der det finnes navn på mer enn ett språk er alle tatt med i name=* (uten suffix) med bindestrek mellom, og i samme rekkefølge som vist i listen ovenfor. Eksempel:
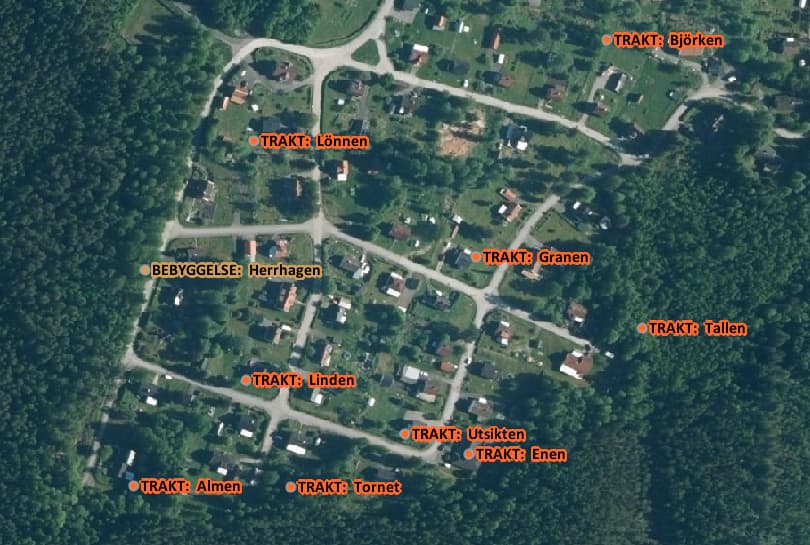
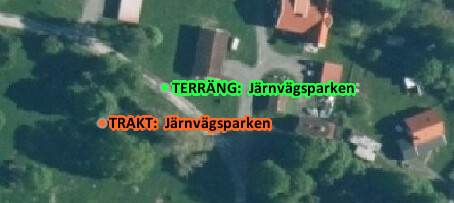
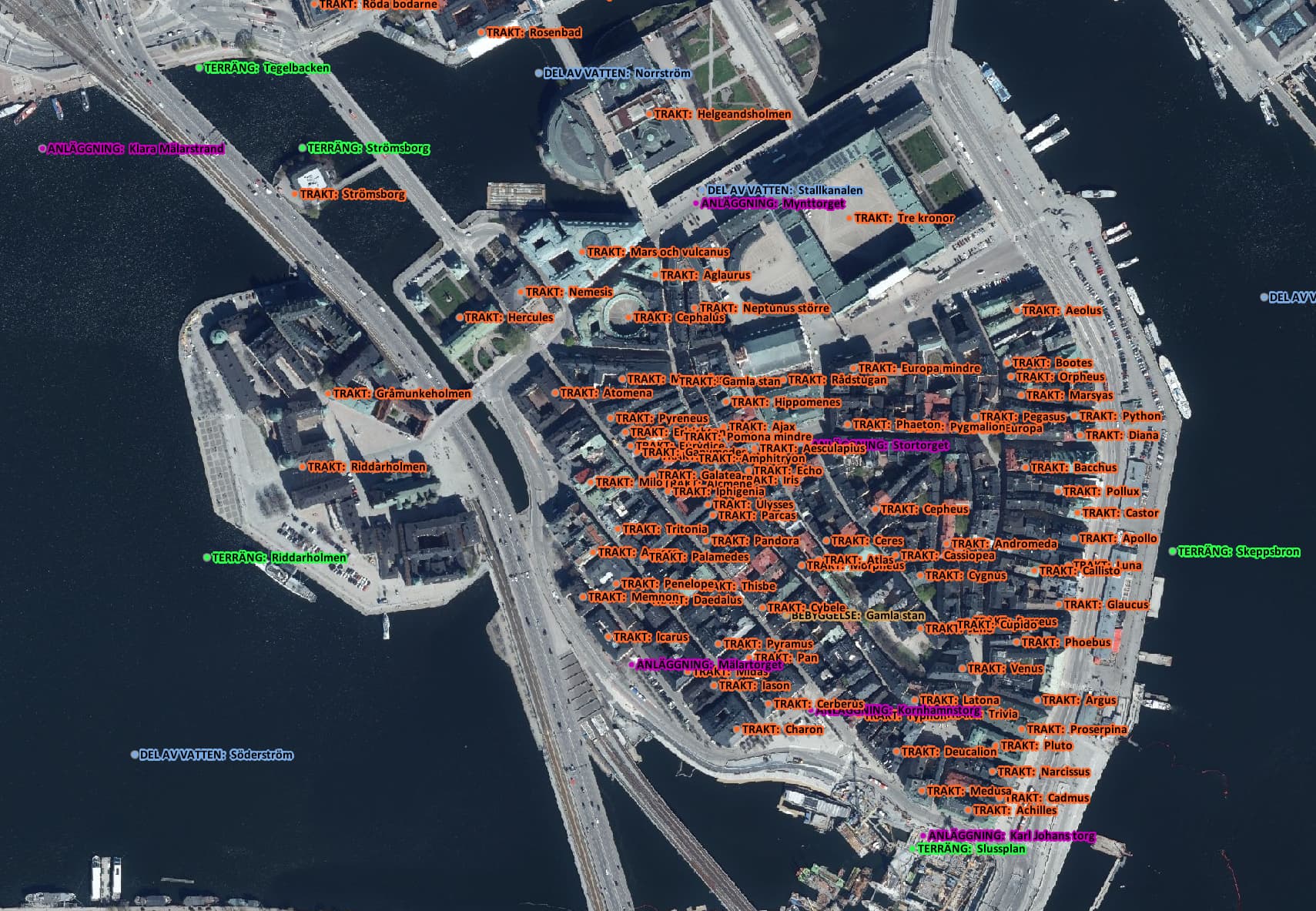
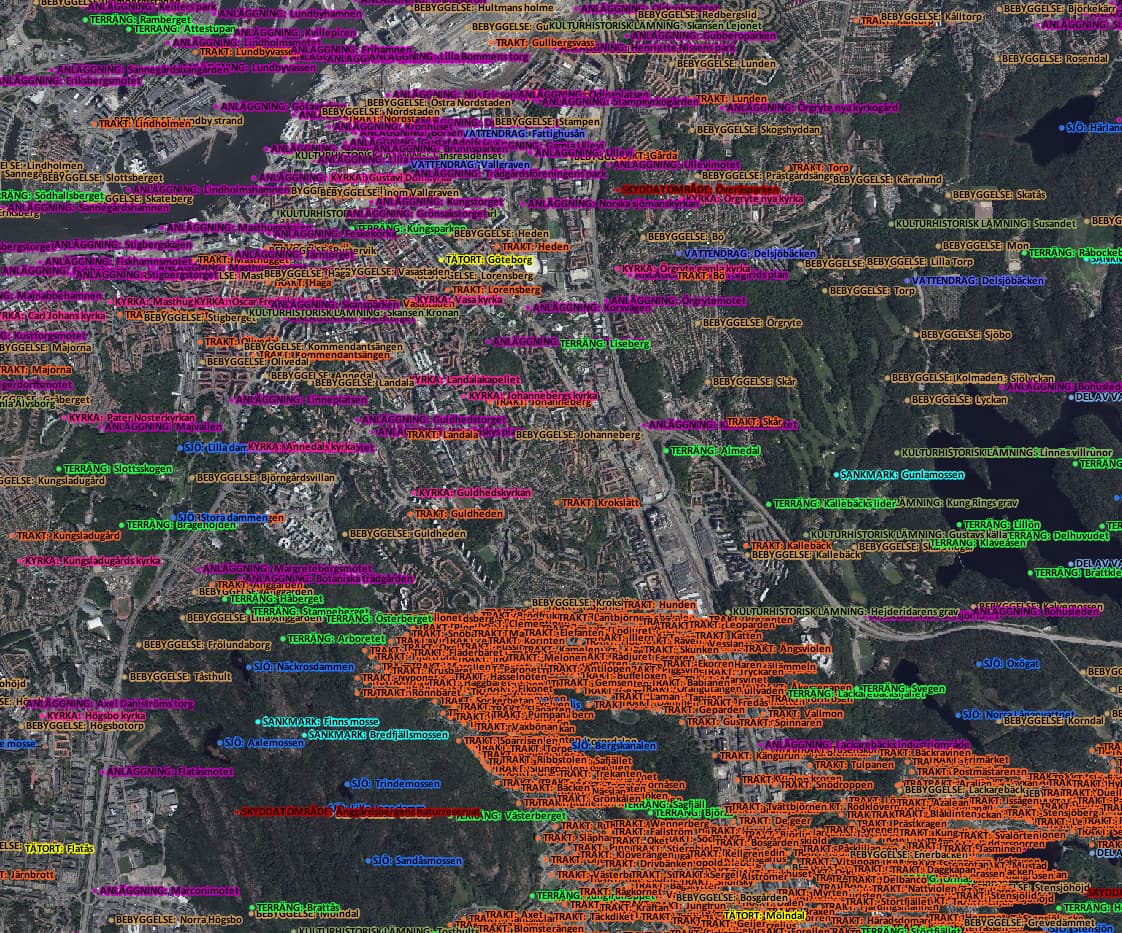
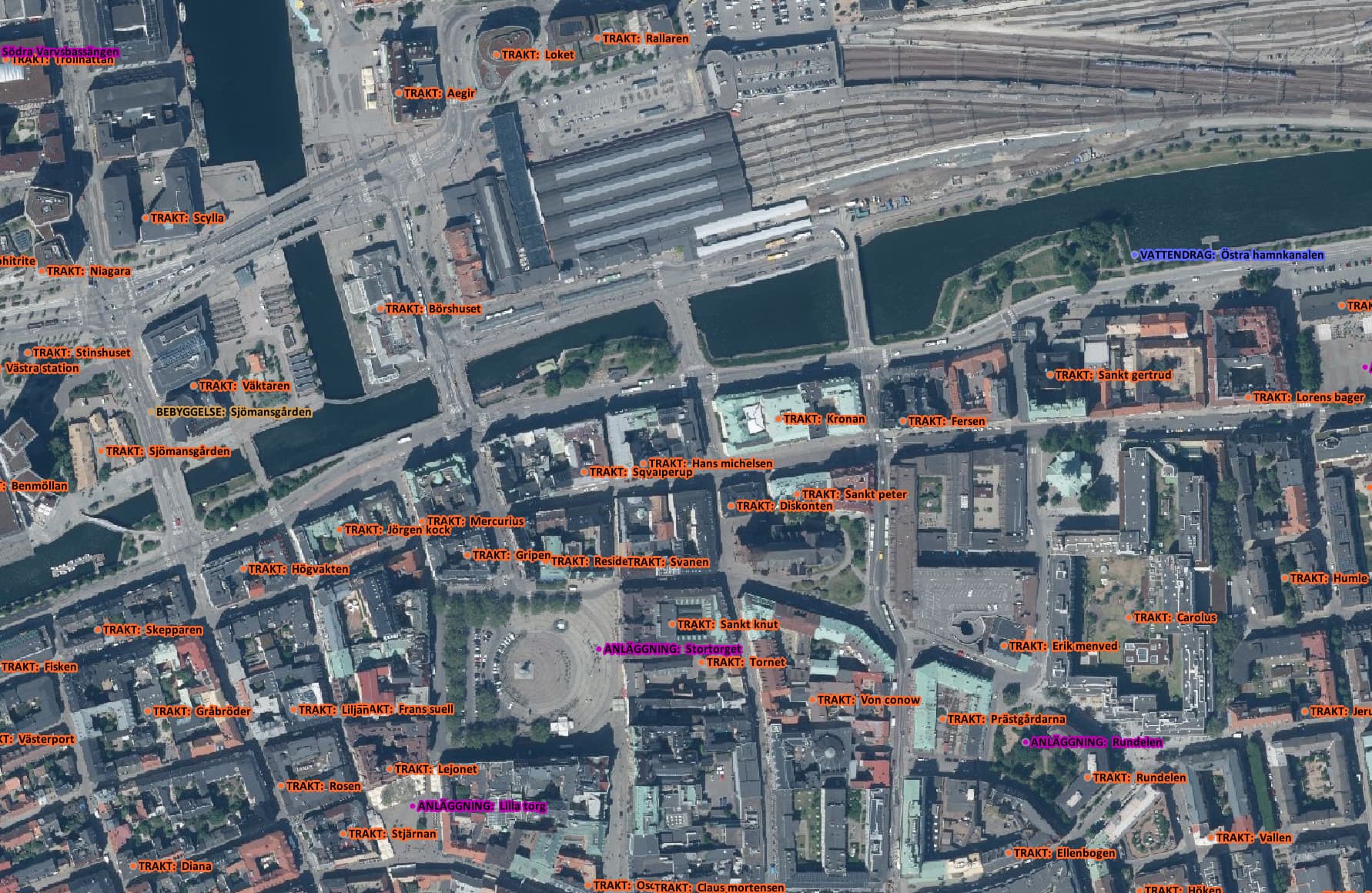
Så lite summerat: Namnen ser ganska ok ut, men det är mycket lägre granulering än vad OSM har. Det är som vanligt varierande taktik från kommun till kommun, och ibland blir det bara konstigt:
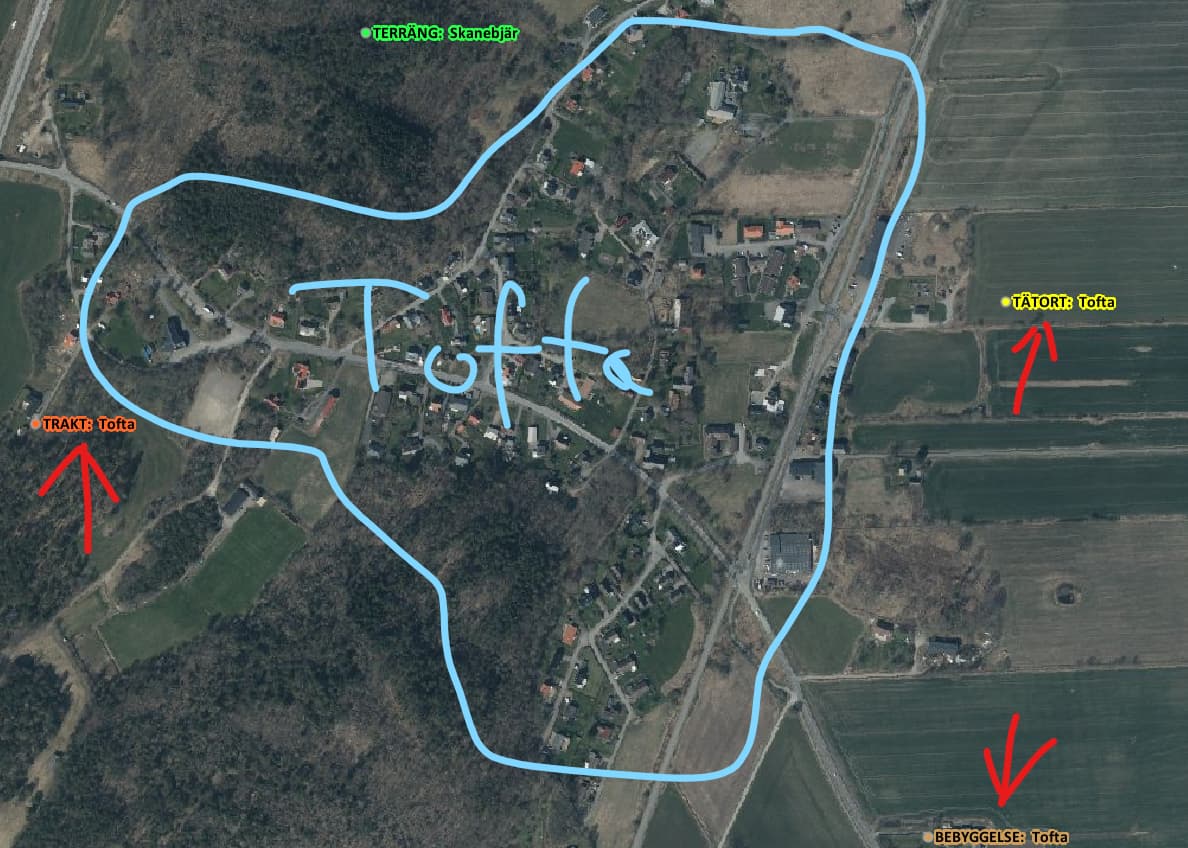
Gissar att det delvis beror på att ortnamnen (liksom det mycket av Lantmäteriets data) ursprungligen enbart samlades in för att visas på en karta och därmed har visst kartografiskt tänk inbyggt. Som i exemplet med Tofta att man placerat namnen utanför för att inte “kolidera” med byggnader o.s.v. i byn.
Vore intressant att göra en avstämning, hur många av Lantmäteriets namn har vi (inom säg 1-2 kilometer)? Hur många har vi extra?
Bra att känna till att Lantmäteriet är ganska hårda i när de accepterar ett nytt ortnamn, vill minnas att en tumregel är att det ska ha varit i bruk i minst 30 år (gäller dock inte nybyggda områden). Så det kan mycket väl finnas namn som är tillräckligt i bruk för att vara med i OSM, men som saknas i Lantmäteriets data.
Etter at vi får bekreftelse fra Lantmäteriet på å bruke CC-BY 4.0 data i OSM kan importsiden legges frem for kommentering fra hele OSM community (utenfor Sverige).
(Har også laget nesten ferdig utkast til importside for Byggnader, men der må jeg få tak i data først).