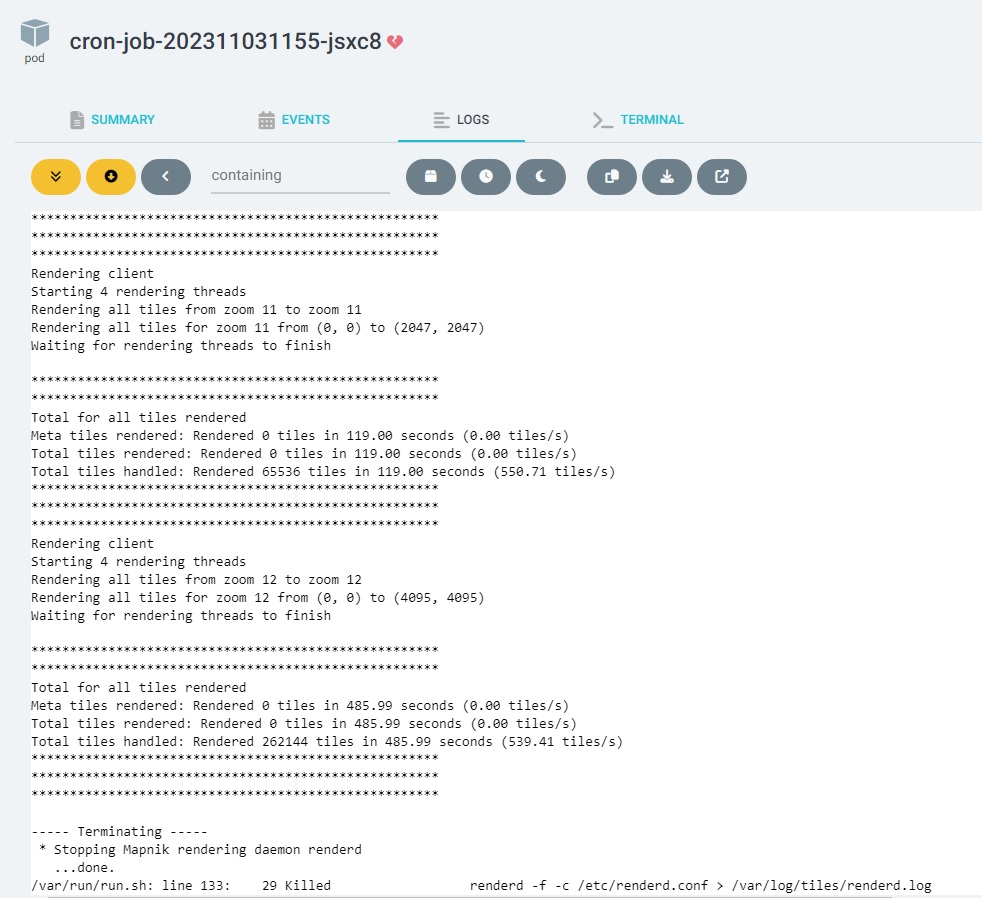
I am trying to prerender a rather small map (Switzerland) with this command:
render_list --all --min-zoom=0 --max-zoom=12 --map=isa --tile-dir=/tiles --socket=/tmp/renderd.sock --num-threads=4
It takes very long to finish and finally crashes with an OOM exception. I actually don’t see that exception - I am running OSM in a pod on k8s and k8s terminates the pod with exit code 137.
I tried increasing the memory of course but that seems to have no impact. I went from 8GB to 32GB but the result stays the same. I would assume that prerendering Switzerland shouldn’t need that much resources…?
What confuses me most is that a top command always seems to show the total memory of the cluster and not of the pod itself:
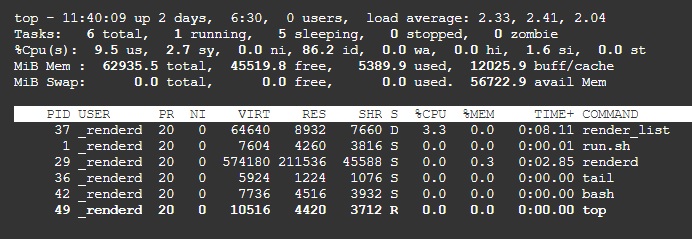
I can see a total of 62935MB here which seems to match (more or less) with the cluster memory of 64GB. Or do I misunderstand something? The pod had 32GB assigned in this run.
In general I wonder if this is really an OOM situation or just a k8s problem as it actually seems to finish the process but crashes when the process exits (cleans up / garbage collects?). Anyone has experienced this behavior already? Any experiences on running this on k8s? Any hints how to debug?