Die zijn al een keer verwijderd door een mapper vanwege politieke redenen. Dat is weer teruggedraaid.
Helaas zijn die Russische transliteraties ook vrij waardeloos. Vaak zijn daar nog verouderde spellingen gebruikt als basis, en lijkt op andere plaatsen de uitspraak niet overeen te komen. Ik gooi ze regelmatig weg wanneer het duidelijk om geautomatiseerde transliteraties gaat. Dat is bij dorpen en buurtschappen meestal zo.
Van de plaatsen in Fryslân verwacht ik andere (buitenlandse) talen eigenlijk alleen bij de elf steden (toerisme), en de dorpen Drachten en Heerenveen (plus misschien nog een verdwaalde Russische watersporter in Grou?).
In Driel en reactie van hem van vanavond is ik kan Arabisch .
Maar met translate heeft ie sensatie of oefening in Arabisch geschreven of dit echt zijn bedoeling is weet ik niet. Maar leuk vindt ie het wel geeft hij zelf aan.
Automatisch vertalen van Nederlandse namen lijkt me niet iets waar wij ons mee bezig zouden moeten houden: dat lijkt me meer een taak van datagebruikers om dat naar eigen inzicht te implementeren.
Transliteratie van plaatsnamen naar niet-Latijnse schriften lijkt me wel iets waar we aan bij zouden kunnen dragen, omdat dat voor zo ver ik weet niet automatisch kan, maar wel handig zou zijn voor bezoekers van Nederland die geen Latijns schrift kunnen lezen (een kleine minderheid waarschijnlijk). Bulgaars (en volgens mijn vrouw ook Russisch) Cyrillisch is puur fonetisch, dus om goed te translitereren moet je de uitspraak weten, en bovendien keuzes maken voor Nederlandse klanken waar geen Cyrillische letter voor is. Dat vraagt de kennis van zaken van een menselijke vertaler. Iemand die het leuk vindt Arabische transliteraties toe te voegen en beweert dat hij dat kan, zou ik z’n gang laten gaan.
Het probleem is dat je dan niet meer objectief de feiten weergeeft. Vertalen is een creatieve bezigheid, waarbij de vertaler keuzes moet maken zoals je aangeeft. OpenStreetMap is in essentie een naslagwerk zoals een encyclopedie; het is niet de plaats waar je zelf nieuwe namen kan aandragen. Er moet iets van een externe bron zijn. Bij OpenStreetMap mag dat ook lokale kennis zijn of een observatie, maar zelf transliteraties maken gaat een grens over.
Ik weet hoe dit werkt met het Japans, en ik draag name:ja bij waar mogelijk. Daarbij beperk ik met tot plaatsen die ook in het Japans omschreven worden. Denk aan de (provincie)hoofdsteden en de provincies, of plaatsen die vanuit het toerisme bekend zijn. Zolang je duidelijke sporen van gebruik kan vinden in de taal die je toevoegt is dat OK. Dat moet wel verder gaan dan een stub-pagina op de betreffende Wikipedia of Wikidata.
Als je dat loslaat krijg je waar we nu mee zitten met name:ru. Ooit massaal ingevoerd door een goedbedoelende mapper, maar het zijn geen gangbare transliteraties wanneer je op het niveau van dorpen en buurtschappen komt.
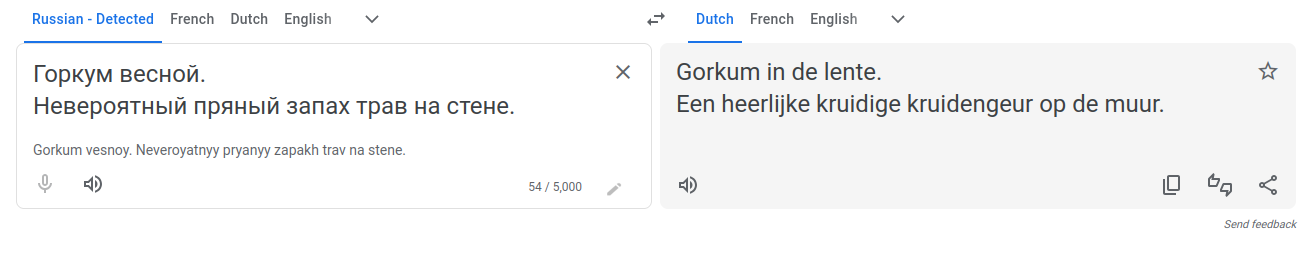
Hier is een leuk voorbeeld van een die verdacht is, Gorinchem:
Voor wie het niet weet, je spreekt deze plaatsnaam uit zoals de alt_name. Maar gooi nu name:ru eens door een conversietooltje en je leest: Gorinhem. Is dat daadwerkelijk de juiste naam, of wordt deze naam massaal gebruikt door half-geautomatiseerd kopiëren? OpenStreetMap wordt samen met Wikidata en Wikipedia namelijk ook als bron gebruikt voor van alles en nog wat, en deze Russische namen staan er al zo’n tien jaar op, maar als je even zoekt zie je dat authentiek gebruik van de plaatsnaam in het Russisch anders lijkt:
Gorinchem / Горкум весной.
Невероятный пряный запах трав на стене.
Een vertaler moet soms keuzes maken die discutabel zijn, maar het is geen vrije creatieve bezigheid: er zijn wel degelijk regels maar die dekken niet alle gevallen. Ik denk dat de graad van vrijheid vergelijkbaar is met die van mappen voor OSM: er zijn vuistregels (beschreven op de wiki) maar ook verschillen hoe verschillende mappers dingen op de kaart zetten. Dat is geen reden om het niet te doen, perfectie moet niet de vijand van het goede zijn.
Wbt. Bulgaars (waar ik het best bekend mee ben): er zijn papieren kaarten van Nederland met Bulgaarse plaatsnamen te koop, en Google Maps is in het Bulgaars beschikbaar (maar wemelt van de fouten, waarschijnlijk door te veel vertrouwen op automatische vertaling), dus waarom geen OSM kaart van Nederland in het Bulgaars? Het heeft geen hoge prioriteit, maar als een in Nederland wonende Bulgaar het leuk vind om plaatsnamen op OSM toe te voegen, waarom niet? Maar je moet er denk ik wel wat van zeggen als hij dat geautomatiseerd gaat doen: menselijke controle is noodzakelijk. En ik denk niet dat het beperkt moet worden tot de grote plaatsen en toeristische trekpleisters: Bulgaarse immigranten vind je overal in Nederland.
Dat maakt voor plaatsnamen verder niet uit. Zodra je gaat vertalen ben je per definitie creatief bezig; je bent aan het creëren in plaats van aan het documenteren.
Dat mag die Bulgaar al! Amsterdam heeft toch ook name:bg=Амстердам? Die naam wordt in het Bulgaars ook zo gebruikt (in kranten en literatuur bijvoorbeeld). De mapper mag alleen niet namen gaan zitten verzinnen. Wat doe je met Hoofddorp? Maak je daar Централен Село van? Oftewel, als we het Engels als voorbeeld pakken, Main Village? Of moet het Главно Село zijn? Head Village?
Je maakt daar creatieve keuzes! Dat mag als vertaler, en als het aanslaat heb je een exoniem gecreëerd, en als die aantoonbaar breed gebruikt wordt, dan, ja dan, mag die op OpenStreetMap. Maar daar zitten jaren, zo niet decennia tussen.
Foutieve data is hoe dan ook niet wenselijk. Als een naam er in een bepaalde taal staat, dan moet je er vanuit kunnen gaan dat die naam ook klopt en geen verzinsel is. Het ontbreken van een taal/naam-tag is ook informatie! Het is compleet logisch dat de meeste dorpen in de wereld alleen maar een endoniem hebben, dus enkel een name=* in de plaatselijke taal. Soms komt daar een tweede taal bij (denk aan Fryslân of Catalonië), en als een plaats echt bekend raakt, dan soms wel meer (Chinees bij Giethoorn!).
Je helpt een Bulgaar er niet mee om namen te gaan zitten opleggen vanuit OpenStreetMap als die niet gangbaar zijn in het Bulgaars. Je kan dan immers niet meer zien of dat de echte Bulgaarse naam is, of een transliteratie zoals al die name:ru waar we nu mee zitten.
Voor automatische transliteratie zou een map frontend wel iets kunnen doen als de gebruiker daar op zit te wachten natuurlijk (en die app zou dan ook duidelijk moeten aangeven dat het om een computertransliteratie gaat wanneer er geen name:bg is). Maar dat hoort echt buiten de data te gebeuren.
Ik geloof niet dat we het snel eens zullen worden. Ik denk dat je de creativiteit van namen in andere schriften toevoegen sterk overdrijft. Geen Bulgaar die het in zijn hoofd haalt om Hoofddorp te gaan vertalen want dat heeft geen enkel praktisch nut. Het enige dat werkt is het te translitereren tot Хофддорп want dan wordt je terminste verstaan als je de weg vraagt. Als dat nodig is kunnen we dat ook als regel vaststellen, en er een tag voor maken die duidelijk maakt dat het een transliteratie is (zoals int_name=* duidelijk maakt dat het een transliteratie naar Latijns schrift van een naam in Cyrillisch of Grieks schrift is).
Ik zal er tzt. een Engelstalige draad van maken, want dit is iets dat internationaal geldt en waar ik wel de mening van de rest van de wereld in wil betrekken.
Amsterdam is als hoofdstad in zo’n beetje elke taal ter wereld wel bekend. Daar zijn dus gangbare transliteraties voor. Het zijn er ongeveer veertig! Die bestaan allemaal ook in de betreffende talen, en zijn op die manier geverifieerd. Dat maakt ze waardevol.
Het is absoluut niet wenselijk om ook voor SchubbekutteveenLutjelollum en al die andere duizenden plaatsen veertig (!) transliteraties te gaan zitten maken op basis van algoritmes of eigen interpretatie. Als je dat wil, moet je dat gewoon aanbieden in een app of andere frontend voor OpenStreetMap.
Ik kan, als iemand die Japans spreekt, ook prima een name:ja voor Lutjelollum maken, maar dat zou volledig mijn interpretatie zijn. Ik maak daarin (creatieve) keuzes qua uitspraak en benadering — een andere vertaler zou wellicht andere keuzes maken. Dat doe ik niet, omdat er nagenoeg geen Japanse bronnen zijn waarin Lutjelollum voor komt, in tegenstelling tot アムステルダム, de provinciehoofdsteden, en diverse toeristische plaatsen.
Als je echt nuttig wil zijn voor Bulgaren, focus je dan eerst op de provincies, de provinciehoofdsteden, en de overige grote steden. Dat Arnhem Арнем heet in het Bulgaars is immers evident, maar name:bg ontbreekt daar.
Sorry for jumping in, but as the author of the mentioned topic, I’d like to clarify that it’s not about “legalizing” individual cartographers’ creative work—translations and transliterations. The discussion is actually about something else: introducing more detailed tagging for transformed names that have oral or written usage and are well-known exonyms or existing foreign-language names.
It seems that my ideas in this discussion haven’t gained much support so far and are receiving constructive criticism. But if anyone has something to add on this topic, I’d be happy to hear it.
Хофддорп is een transliteratie van Hoofddorp: het is nog steeds Nederlands, maar geschreven in een schrift dat voor de Nederlandse taal ongebruikelijk is. De Bulgaarse vertaling zou Главно село zijn, maar het lijkt me duidelijk dat het geen goed idee is om dat op de kaart te zetten: zelfs een Bulgaar zou het eerst terug moeten vertalen naar het Nederlands voordat hij begrijpt waar het over gaat.
Een voorbeeld de andere kant op: de Oekraïense stad Чорнобиль die we in Nederland kennen als Tsjernobyl maar op OSM getagd is als name:nl=Tsjornobyl. Daar kun je een lange discussie over hebben, bijv. of het niet Tsjornobiel zou moeten zijn (komt dichter bij de Oekraiense uitspraak). Voor het Engels zijn er 2 tags: name:en=Chornobyl (transliteratie volgens de regels van de Engelse taal van wat er op het plaatsnaambord staat) en alt_name:en=Chernobyl (zoals het algemeen bekend is in het Engels). alt_name:nl=Tsjernobyl toevoegen lijkt me een goed idee. Maar wat we in ieder geval niet moeten doen is het op de kaart zetten als Zwarte Stengel of Bijvoet, want dat zijn vertalingen waar niemand wat aan heeft.
Ik denk dat er wel verbeteringen mogelijk zijn in hoe we zoiets taggen op OSM, zodanig dat het duidelijk is of iets een vertaling of een transliteratie is. Als we bijv. name-Cyrl=Амстердам zouden kunnen taggen voor Amsterdam, zouden we 20 tags kunnen vervangen en alleen name-Cyrl:be=Амстэрдам en name-Cyrl:be-tarask=Амстэрдам nog moeten behouden.
Ik denk dat we kunnen afspreken dat voor Nederlandse namen in andere schriften dan Latijns, we moeten translitereren en niet vertalen, tenzij er een breed gebruikte naam is in de taal die het andere schrift gebruikt en afwijkt van de transliteratie (wat weinig voorkomt). Voor translitereren zijn er normen, dus dat zal niet al te veel discussie opleveren.
Goed, ik leg het nog een keer uit. Transliteren is het schrijven van een woord in een ander schrift, met behoudt van de uitspraak. Afhankelijk van het schrift kun je hiervoor vaak met een vaste set regels redelijk goed in de buurt komen van de bronuitspraak.
1
Dat werkt echter lang niet altijd vlekkeloos. Er is geen enkel transliteratiealgoritme wat met Gorinchem overweg kan. Daar moet je eerst omzetten naar de spreektaalvariant (‘Gorkum’, grofweg). Dat is al een keuze waar je kennis voor nodig hebt. Je moet voor alle Nederlandse bronnamen dus eerst de uitspraak weten.
2
Je moet per taal met een afwijkend schrift dus een keuze maken voor een transliteratiesysteem. Zelfs binnen één systeem kunnen er meerdere stilistische of culturele keuzes zijn.
3
Wanneer de bronuitspraak die je om wil zetten helemaal niet een-op-een kan in het doelschrift, moet je weer een creatieve keuze maken. Hoe benader je die klank? Wat doe je met de â in Earnewâld? Het Bulgaarse schrift geeft je een beperkt palet aan klanken.
Wat maak je van Eastermar? (Als je de uitspraak hier begint met een Engels ‘East’ ga ja al de mist in.) Gorinchem? Quatrebras? Zie ook weer punt 1.
4
Namen worden niet alleen nu overgenomen in een andere taal. Sommige exoniemen gaan eeuwen terug. Zijn in het Bulgaars alle bekende plaatsnamen voorzien van de moderne hedendaagse Nederlandse uitspraak? In het Nederlands spreken we vaak nog van Berlijn en Parijs in plaats van Berlin (met de ie-klank) of Paris (ie-klank, en de ‘s’ hoor je niet). Dat is historisch zo gegroeid. Ook in andere talen waarin transliteraties gebruikt worden komt dit voor. Hoe denk je dat Nederland heet in het Japans? オランダ, oftewel, ‘Oranda’. Daarmee bedoelt men nu niet Holland, maar daar is de naam wel van afgeleid omdat deze in de 16e eeuw als exoniem ontstond vanuit het Portugees.
Dit kan in elke taal gebeuren. In de name-tags zetten we daarom alleen de exoniemen die ook echt gangbaar zijn. Je kan anders vanuit de data niet zien of je met een valide exoniem te maken hebt, of een verzinsel van een goedbedoelde mapper.
Voorbeeld uit het Bulgaars: Den Haag. Volgens jouw methodiek is dat Ден Хааг, maar dat is onzin, want het Bulgaars hééft hier een gangbaar exoniem voor: Хага.
Door bij elke plaats name:bg te kidnappen voor een eigen transliteratie negeer je potentieel bestaande exoniemen, en ontneem je data-consumers de mogelijkheid om te begrijpen of iets een exoniem is, of slechts een automatische transliteratie. Je vervuilt dus de data.
5
Je negeert dit punt uit mijn eerdere post, maar Amsterdam heeft nu al zo’n veertig name-tags in een ander schrift dan het Latijnse. Wat je hier voor het Bulgaars voorstelt, geldt ook voor een groot deel van die andere talen.
Dat leidt tot een situatie waarin Schubbekutteveen Lutjelollum plotseling veertig transliteraties erbij krijgt. Wat moet je als mapper dan doen als je een fout ontdekt? Lutjelollum wordt nu op de komborden plots toch met een spatie geschreven bijvoorbeeld? (Merk op dat de plaatselijke straat namelijk ‘Lutje Lollum’ heet in de BAG, en daarmee het kombord tegenspreekt.) Wat moet je nu met al die transliteraties? Moeten die actueel gehouden worden met de bronnaam, omdat het geen echte exoniemen zijn, of moet je die zo laten, omdat in de doeltaal nog steeds over het gehucht zonder een spatie geschreven wordt? Dat is de situatie die we nu hebben met name:ru namelijk.
Bij een gangbaar exoniem kun je dit gewoon uitzoeken, want het gebruik ervan is immers verifieerbaar.
6
Ja, dat kan, maar dan heb je alsnog het onderhoudsprobleem van punt vijf. Veertig van die tags op elke plaatsnaam in Nederland. Ook hier weet je immers niet of het een valide exoniem is (Хага) of een automatische transliteratie (Ден Хааг). Of wou je in name-Cyrl:bg dan echt Ден Хааг invullen?
7
Ja! Nu snap je het! Taal is hartstikke politiek. Om daar objectief mee om te gaan is soms een uitdaging. Je hoeft alleen maar te kijken naar Kyiv om te begrijpen dat ook in het Nederlands een exoniem kan veranderen. In vijf jaar tijd zijn alle grote kranten en de meeste andere media van Kiev naar Kyiv gegaan in het Nederlands. Dat was vaak een politieke keuze. Die keuze maken wij op OpenStreetMap niet, maar wat we wel doen, is de werkelijkheid volgen. Daarom is name:nl nu inderdaad Kyiv, en is er een old_name:nl=Kiev. Dat zou vier jaar gelende nog controversieel geweest zijn. Nu is dat gangbaar en zou het in stand houden van Kiev juist controversieel zijn.
Dit soort zaken zijn complex. Als het even kan beperk je dat dus tot plaatsen waar daadwerkelijk een exoniem voor bestaat.
8
Wat je wil, kan nu al opgelost worden in een frontend. Wil je automatische transliteraties aanbieden? Kijk of daar interesse voor is in OsmAnd of OrganicMaps. Je gebruikt dan een algoritme om de name-tags aan te vullen wanneer ze ontbreken in jouw doeltaal. Je biedt dan de gebruiker ook de mogelijkheid om het uit te zetten.
Je kan ook een eigen kaart van Nederland maken aangevuld met transliteraties waar name:bg ontbreekt. Perfect voor Bulgaren die moeite hebben met de uitspraak.
9
Is dit überhaupt iets waar gebruikers op zitten te wachten? Als ik een name:nl aantref, verwacht ik dat ik daar met het gangbare exoniem te maken heb (Berlijn bijvoorbeeld). Waarom zou een Bulgaar dat niet van name:bg verwachten? Voor plaatsen waar dit ontbreekt heeft die vast wel een bookmark voor Translit BG - Bulgarian Transliteration and Spell Checker of een andere tool paraat toch?