import requests
from bs4 import BeautifulSoup
import sys
import json
sys.stdout.reconfigure(encoding='utf-8')
start_page = 1
end_page = 88268
url_template = "https://help.openstreetmap.org/questions/{page}"
data = []
for page in range(start_page, end_page + 1):
print(page)
url = url_template.format(page=page)
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
element = soup.find(id="CALeft")
data.append({'id':page,'text':str(element)})
with open('qnadump.json', 'w') as f:
json.dump(data, f)
Then, copy qnadump.json, style.css, and r.py into the “questions” subfolder on htdocs.
r.py :
import json
import sys
import os
sys.stdout.reconfigure(encoding='utf-8')
with open('qnadump.json') as f:
data = json.load(f)
for i in data:
nya = '<meta charset="UTF-8"><link rel="stylesheet" type="text/css" href="../style.css">' + i['text']
os.makedirs(str(i['id']), exist_ok=True)
file_path = os.path.join(str(i['id']), 'index.html')
with open(file_path, 'w', encoding='utf-8') as file:
file.write(nya)
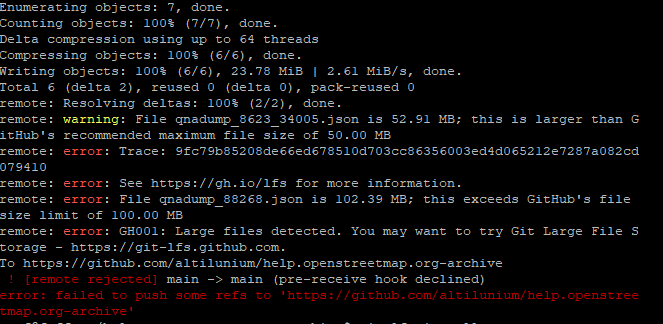
Run r.py there. It will generate a lot of folders, like this one (although I stopped the process after creating only two for this example below) :
By using that shell account, I can create a static site clone. But where should I submit that static site so it can be deployed properly? (probably replacing the old Django-based help.openstreetmap.org with a static site)
C. Some of the files are still hosted on help.openstreetmap.org (and not scrapped). Make sure that all of this files are not deleted when turning off the OSQA django instance.
Note it is also possible to host web content directly under your user on the dev server. eg: https://rtnf.dev.openstreetmap.org/ serves the contents of /home/rtnf/public_html/ directory.
I noticed that both the user profile and tagging functionalities are disabled in the archived version of the Wireshark forum (reimplementing both features using static HTML is quite a challenging task, and they seem to be giving up altogether on this.).
The last problem in my implementation is likely to be the URL change, which could probably be fixed by using Apache’s mod_rewrite (for example, automatically redirecting “/questions/88266/osm-carto-multilingual-tags” to “/questions/88266”). Additionally, I need to (1) add a link to the homepage on each answer page, allowing users to navigate back, and (2) make visual improvements to the homepage.
Update 3 : All of the old URL can now be preserved (by automatically redirecting “/questions/88266/osm-carto-multilingual-tags” url format to “/questions/88266”)
If we aren’t going to archive user pages is there going to be an email to all users that they have XXX days to go there and manually archive their contributions?
I had a go at this for mine before the original shutdown date and a really janky version of it kinda sorta works with httrack (would be way easier if the number of results per page was increased significantly).