In this case, the name:uk-t-ka=* and name:uk=* tags match, so is the point of the former to confirm that the latter is based on what’s in name:ka=*? How is this relevant to the map feature? We don’t need it for bookkeeping purposes, since the Ukrainian name already appears on the sign. There also doesn’t seem to be a dispute involving this shop.
Is it the case that Ukrainian speakers pronounce a word one way if it comes from Russian but the identical word a different way if it comes from Georgian? This does happen sometimes in English by coincidence, but tagging the pronunciation in IPA is more directly useful than figuring out the provenance of a surname. That said, better pronunciation was a handwavy rationale I once gave for name:etymology=*, which could technically apply in this case.
In recent times, I have been paying attention to exotic restaurant, fast food, and shop names in Ukraine and discovered that this tag is often applicable. However, in my mapping, the name:uk and name:uk-t-ka tags match because I understand that -t- tags are new and no software currently supports them, unlike name:uk. Ideally, name:uk-t-ka would be sufficient without the existence of name:uk.
This tag better explains the origin of the “exotic” Ukrainian-language name of the restaurant. The -t-ka tag adds value to this name by branching it from name:ka, where the Georgian word meaning “guest” is found. This way, it informs data consumers that the names are not equivalent but rather that one is primary and the other is derived. The fact that it is difficult to imagine a data consumer who would find this distinction important does not mean that such consumers do not exist or will not appear in the future.
Additionally, I do not view this category of tags as something that should be used only in cases of disputes, nor do I consider such tags “less worthy” of OpenStreetMap than name:etymology.
Unfortunately, I do not know of any words that are identical in both Russian and Georgian. As far as I understand, these languages are quite different from each other. However, I can say for certain that the transcription of foreign words into Ukrainian and Russian Cyrillic differs. For example, if we take the restaurant name, in Ukrainian, it is “Стумарі,” whereas in Russian, it would be “Стумари.”
No one is suggesting that you need to identify an existing data consumer that supports the proposed tagging – that would be a chicken-and-egg scenario. However, your idea would benefit from a hypothesis about a potential future use case, which enables the community to validate or invalidate the idea, as we did with your mockup of Mount Paektu.
If you’re holding onto a piece of knowledge that we don’t have an established tagging scheme for, but you don’t have a concrete use case for it yet, then the way OSM traditionally handles it is “any tag you like”. In other words, go ahead and use the extension syntax, but don’t expect anyone to go along with it until you come up with a rationale that others find compelling. Otherwise, we risk spending time on exotic tagging schemes “just in case” that distract mappers and developers from more immediately practical aspects of the map.
I will try to provide my hypothesis about the future use of such data for business names, just as I did with exonyms in New Zealand and Mount Paektu.
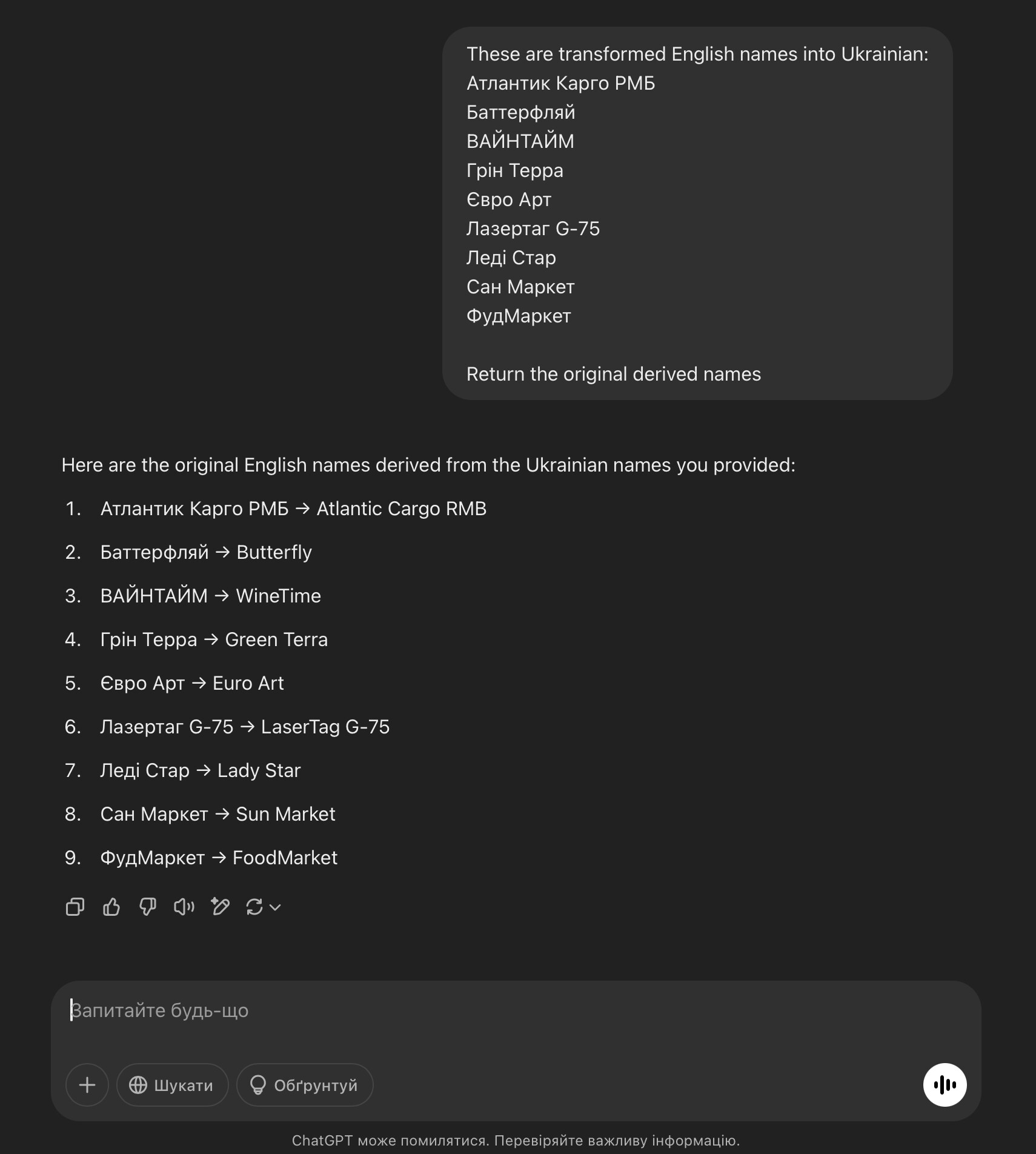
As we know, every major city in the world has numerous businesses with a wide variety of names. These businesses are typically tagged with only name, and sometimes name:<lang>, which indicates the language of the name. Here are some examples of business names in Ukrainian from the Podil district of Kyiv: Komilfo (uk-Latn), Атлантик Карго РМБ, Баттерфляй, ВАЙНТАЙМ, Євро Арт, Лазертаг, Лазертаг G-75, Леді Стар, Сан Маркет, ФудМаркет, Венето, Престо, Профектум, Атман.
However, any Ukrainian speaker would immediately recognize that all these names have been adapted from other languages. In reality:
Names derived from English: Атлантик Карго РМБ, Баттерфляй, ВАЙНТАЙМ, Євро Арт, Лазертаг, Лазертаг G-75, Леді Стар, Сан Маркет, ФудМаркет.
Names derived from Italian: Венето, Престо; from Latin: Профектум; from French: Komilfo (uk-Latn); and from Sanskrit: Атман.
Now, imagine if all adapted names in a city were tagged accordingly. This would provide insight into the level of linguistic globalization in that city, as well as the influence and spread of different cultures. It would allow comparisons between cities based on these indicators. If a city has neighborhoods similar to the “Chinatowns” in American cities, this would become evident through business names. Heatmaps could be created to visualize the distribution of such names and analyze whether they are spread evenly or concentrated in certain areas.
Of course, this is just a hypothesis, but I suspect that in cities like Seoul, there would be a significant number of names that have actually been adapted from other languages into Korean:
No. You shouldn’t confuse the surname McDonald with the McDonald’s restaurant chain. What specific language tag would you use for the name of McDonald’s restaurants in the US?
I wouldn’t use any specific language tagging for a McDonald’s restaurant located anywhere, I would just tag it name=McDonald's. (or whatever the local writing system happens to use)
In Ukraine, the signs on these restaurants also say McDonald’s, so that should go into the name tag as well. However, the Ukrainian Cyrillic version—МакДональдз—appears in ads and on the website, so it definitely belongs in name:uk. The tag for the transformed name can be used if we consider McDonald’s to be the official name of the restaurant chain in English. In that case, name:en and name:uk-t-en would be appropriate.
I think I see what you’re getting at, but it would be quite unreliable. Most Chinese businesses I’ve mapped, whether inside or outside a Chinatown, have English names that are only somewhat related to the Chinese name, so I don’t know how literally I would need to tag the -t- codes. Businesses named after people have parallel names in each language; it’s kind of pedantic to say that one comes from the other. Some random examples that I’ve mapped:
If we take these examples, you are right. Many of these names can be considered parallel rather than derived from one another.
In Ukraine, there are cases where only a Ukrainian Cyrillic transformation of an English name exists, while the original English spelling is never used. For example, this is the case with the Баттерфляй cinema chain. If we strictly follow OSM principles, adding name:en=Butterfly to such an object would not be correct since this spelling does not appear on any signs or advertisements.
In such cases, I believe the additional tag name:uk-t-en=Баттерфляй would be very useful.
The fact that Баттерфляй is a transliteration of butterfly wouldn’t necessarily lead English speakers to call it “Butterfly”. A more literal transliteration of the sort Unicode envisioned for en-t-uk might be “Batterflyai” (?). But I see that the cinema chain does use “butterfly” in its domain name, and it’s reasonable to assume that this is English as opposed to some other Latin alphabet. If they don’t post it anywhere physically, name:en=Butterflyname:en:signed=no would be appropriate.
Thanks, I didn’t know about the name:signed=no tag. However, the topic here is about specifying what Баттерфляй refers to in more detail rather than just using name:uk, and the tag you suggested won’t achieve that
By the way, your example with Batterflyai helped me realize that it will be easier for developers to understand that the content of the name:uk-t-en tags should not be transliterated into Latin again to avoid further distortion of the information. Instead, somehow—perhaps with the help of specialized AI mini-models at the data processing stage—it would be possible to “restore” the original Butterfly from the Cyrillic Баттерфляй:
would greatly reduce anyone’s reliance on an LLM to come up with answers to this very question.
Some in the OSM community insist that only the languages somehow spoken “on the ground” should be represented in explicit tags. This is motivated by a sense that all the languages for all the features would be too much overhead for a local community that speaks only one or two languages (ignoring the possibility of language communities helping from afar). As a result, the ecosystem around OSM has a decade of experience in pairing OSM with Wikidata, which is more accepting of translations and transliterations.