Tag zusammen,
ich beschäftige mich mit der Frage, wie man zweisprachige Namen auf eine Karte bringt, also sowas wie “Athen (Αθήνα)”.
Dabei entstehen natürlich recht lange Namen, die beim Rendern umgebrochen werden. Solange die Schrift in eine Richtung läuft, ist das kein grosses Problem: Man bricht an jedem Leerzeichen um, oder vielleicht nochmal an der Sprachgrenze, damit die Sprachen mit etwas Glück in je einer Zeile bleiben.
Aber was macht man mit Sprachen, deren Schreibrichtung gegeneinander läuft?
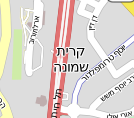
Meine ersten Versuche laufen jedenfalls schief. Ich nehme den Namen in lateinischen Buchstaben, hänge den z.B. hebräischen dran und werfe das Mapnik vor. Mapnik liest von links nach rechts und bricht ohne Rücksicht auf die Schreibrichtung um. Das letzte Wort des hebräischen (also das linke) landet dann in der oberen Zeile. Aus Kirjat Schmona / קרית שמונה wird dann das da:
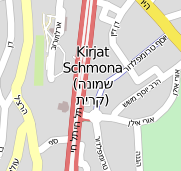
Dabei sollten meinen nicht vorhandenen Hebräischkenntnissen (und dem Zeilenumbruch der Wikipedia) zufolge das hier die korrekten Schreibweisen sein:

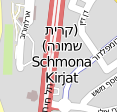
Ein Vergleich mit der Katrte der Geofabrik half auch nicht weiter, die macht wohl einen ähnlichen Fehler, nur dass sie den lateinischen Text verwürfelt. Lyrk, zumindest in dem Stil, den graphhopper verwendet, scheint auch der Geofabrik zu folgen.
Hat irgendwer eine Idee, wie man die beiden Schreibrichtungen sinnvoll unter einen Hut bringen kann? Mir fällt nur ein, den Umbruch zu verbieten oder den Fehler zu übersehen.
Grüße, Max
PS: Probleme mit Schriften, die von oben nach unten laufen, übersehe ich einfach, auch wenn es interessante Designideen dazu gäbe… ![]()