tl;dr: Ich find’s gut, bin dabei 
Hallo gormo,
warum du da jetzt so Docker-fixiert die Tätigkeiten aufschreibst erschließt sich mir nun auch absolut nicht. Und dass du dann selbst dich genau bei dem Part zurückziehst ist schon merkwürdig komisch 
Ich finde die Idee gar nicht schlecht, dass man quasi auch mal von der Karte (Geokoordinaten / “räumlicher Index”) ausgehend halt auf Diskussionen zu dem Gebiet kommen kann. Vor allem weil man damit auch dagegenarbeitet, dass zur selben Sache neue Diskussionen beginnen. Auch hilft’s schneller gemappte Dinge gleich besser einzuordnen.
Würde es aber es anders/flexibler gleich aufbauen. Ein Punkt ist halt: wieso nur Forum? Gibt doch noch andere Diskussionsorte (Mailingliste, Help, Changelog-Diskussionen, Note-Diskussionen, Benutzerblogs, …).
Dann sollte es mit Sicherheit auch eine Filtermöglichkeit bezüglich dem Zeitraum geben, denn sonst ist die Karte in manchen Bereichen wohl arg geflutet.
Ebenso wenn auch Relationen mit reinfließen, sollte man irgendwie auch grob das betroffene Gebiet/Gebietsgröße mit in der Datenbank haben, sodass man auch daran rausfiltern kann. Denn wenn ich wissen will, was lokal zu einem Bereich diskutiert wird, will ich keine Diskussionen zu Relationen, welche einfach so großflächig sind, dass es mit reinfließt.
Daneben ggf. noch Sprache mit erfassen (sofern feststellbar).
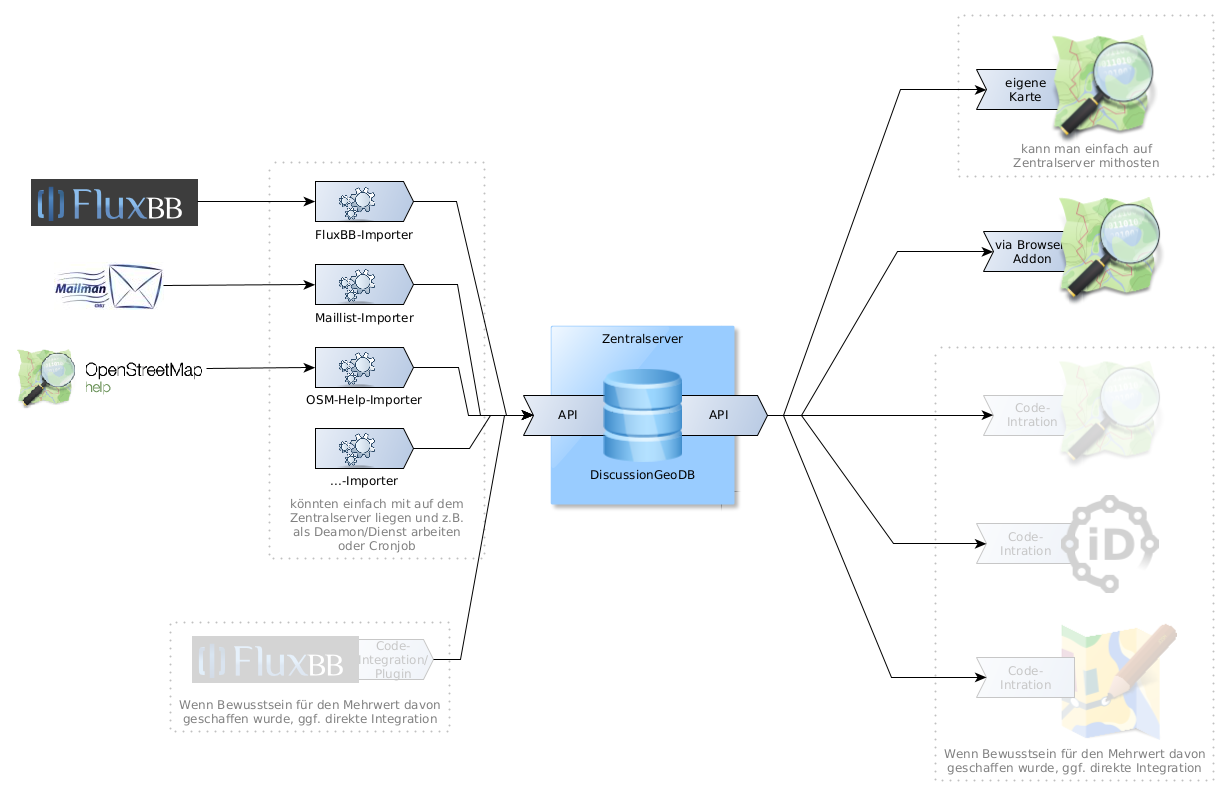
Dementsprechend würde ich das ganze modular aufbauen:
Im Kern die Datenbank, in welcher halt entsprechend dem oben genannten folgendes erfassbar macht (und ggf. Erweiterungen weiterer Quellsysteme oder Eigenschaften gut offen bleibt):
-
Quelle (Forenpost, Maillingliste, Help, …)
-
Zeitpunkt
-
OSM-Objekt (sofern direkt referenziert)
-
Geo-Zentralpunkt & Bereich
-
Sprache (sofern feststellbar)
Dann muss man halt die o.g. Systeme nach und nach anbinden. Hierbei könnten die o.g. Systeme natürlich theoretisch selbst mitteilen, was neu ist - aber das wird wohl so schnell nicht passieren - oder halt aber man baut Programme welche regelmäßig die Quellsysteme durchleuchtet nach neuem (bzw. initial halt einmal vorhandenes durchsucht).
Egal welches System man durchsuchen will, erstmal muss man gang klar definieren, woran man
konkret erkennen möchte? Denn jegliche Änderungen an den “Aufnahmekriterien” würde ein kompletten Datenbank-Neuaufbau bedeuten mit erneuten kompletten durchsuchen. Das sollte man unbedingt vermeiden. (Dazu dann ganz unten weiter)
Ein Programm welches halt unsere Datenbank aus dem Forum befüllt braucht ja nicht unbedingt zugriff auf die FluxBB-Tabellen. Hier reicht’s ja eigentlich initial einmal alles via HTTP-Requests abzufragen (selbstverständlich mit genügend Delay zwischen allem *) und dann via FluxBB-Schnittstelle (z.B. diese für ein Forum oder für Forum) halt immer am Ball bleiben.
Auch könnte oder sollte man eine saubere API für die Eingabe schaffen. Einerseits nutzt man sie dann selbst für die selbstgeschaffenen Eingabeprogramme, andererseits kann man so vl. tatsächlich o.g. Systeme so direkt anbinden (wäre natürlich ideal wenn ein Plugin für FluxBB z.B. bei einem neuen Post über die API einerseits die Aufnahmekriterien sich zieht und dann halt im Positivfalle halt aktiv via API in die Datenbank einträgt).
Wir können ja erstmal exemplarisch mit dem Forum anfangen und dann erweitern um …
So, dann haben wir schonmal alles in der Datenbank, jetzt wollen wir’s visuell haben. Das es gleich mal eben in osm.org aufgenommen wird, bezweiiifel ich mal sehr stark 
Auch hier sehe ich eigentlich eine API als erstes. Daran kann man dann einerseits eine eigene Karte anbinden, aber genausogut auch z.B. ein Grease-/Tampermonkey-Script oder Browser-Addon welches es auf osm.org/de einbindet. Somit kann man es schonmal gut visuell demonstrieren und wer will es auch einfach nutzen. Ebenso kann man hier erste Erfahrungen sammeln und die UI optimieren bzw. schauen wie’s am idealsten wohl bei osm.org/de eingebunden sein könnte (ohne z.B. gleich zu technisch/aufdringlich für Laien/daran Uninteressierte zu sein).
Dank der API kann es dann auch in weiteren Tools eingebunden werden wie iD, JOSM oder halt auch auf osm.org/de (wenn die Community/Admins letztlich von der Sinnhaftigkeit überzeugt sind)
Könnte mir es in Gänze also so vorstellen:
Natürlich setzt man nicht alles auf einen Schlag um, Fängt halt in der Mitte an, dann ein erster FluxBB-Importer und eine einfache Kartenausgabe. Dann baut man es aus.
Aufnahmekriterien
Wie schon erwähnt, eigentlich allem voran würde erstmal stehen, dass man ermittelt, woran man Objekte (also Foren-Beiträge aktuell) sicher erkennt, dass man sie aufnehmen möchte in den Index?
Hier sollten wir erstmal Beispiele sammeln:
-
OSM-Objekte via URL:
https://www.openstreetmap.org/way/12345/
https://www.openstreetmap.org/relation/12345/
https://www.openstreetmap.org/node/12345/
https://www.openstreetmap.org/note/12345/
https://www.openstreetmap.org/changeset/12345/
jeweils egal ob http(s), noch mit history oder weiteren Hash/Parametern und auch egal ob URL ausgeschrieben oder mit Text (Note)
-
Objekte ohne URL:
Wenn “Node 12345” oder “Node #12345” im Text steht - ohne URL, welche weiteren Text-Notierungsarten gibt es?
-
Ggf. overpass-turbo-Links?
Könnte man ja ggf. ausführen lassen (ja mit viel Delay, über Tage/Wochen hinweg *). Halt nicht selten wird ja auch darüber auf lokale Sachen hingewiesen. Zumindest sollte man einfach erstmal mit aufnehmen in welchen Beiträgen welche overpass-turbo-URLs sich befinden, wenn man eh schon alles durchsucht. Dann kann man später entscheiden ob man den Weg auch gehen will, ohne erneut Forenbeiträge durchsuchen zu müssen. Quasi landet erstmal seperat unter “ToDo”
-
Geokoordinaten:
Kann man jetzt fest mit bestimmten URL-Patterns verknüpfen wie https://www*.*OpenStreetMap53.0000/13.0000 oder halt auch einfach grundsätzlich nach “xx.xxxx/yy.yyyy” suchen? Woher dann aber wissen was long/lat jeweils ist?
Sinnvoll wäre also schon grob schauen ob etwas eine long/lat-Kombi sein könnte. Dann schauen ob auch ein URL-Pattern (osm.org, osm.de, opentopomap.org, gk.historic.place, …) erfüllt ist (wodurch dann long/lat klar erkennbar ist). Wenn kein URL-Pattern gefunden kommt es erstmal in eine extra-DB-Tabelle “ToDo”.
-
externe Dienste aus denen ggf. eindeutige Geokoordinaten ermittelbar sind, wie mapillary.com, uMap
vermutlich auch erstmal in’s ToDo.
Welche gibt’s noch, welche regelmäßig auftauchen?
-
Ortsnamen würde ich ausschließen: 1. Ist das nicht gerade einfach feststellbar, was ein Ortsname ist und 2. wohl kaum sicher, dass es relevant auch um den Ort dann geht.
-
Was halt noch???
Datenbank
Entsprechend dem o.g. würde ich die Datenbank ggf. so aufbauen:
ok, nicht mehr heute ^^
Habe da aber schon grob eine einfache/flexible Struktur im Kopf. Auch halt mit einer Markierung für ToDo-Datensätze, welche noch nicht via API ausgegeben werden, aber man hat halt schonmal erfasst in welchen Beiträgen durchaus noch was drin sein könnte, man muss halt dann nur dafür noch die Erkennung verfeinern (z.B. zusätzliches URL-Pattern für Geokoordinaten aufnehmen).
“false positives”
Was mir gerade noch einfällt: Ich könnte mir vorstellen, dass es durchaus nicht wenige “false positives” geben wird. Also gerade diese ganzen “Guck mal hier, da hab ich das so gemacht”-Beiträge. Die würden dann ja mit dargestellt werden, aber eigentlich ist das ja dann gar keine Diskussion um dieses Objekt dann. Vl. sollte man also auch die Möglichkeit schaffen, dass sowas rausgefiltert werden kann? Also z.b. über ein Meldesystem
Besser wäre natürlich gleich von vorn herein festzustellen, welche Beiträge eigentlich thematisch nicht um das Objekt/Region sich drehen, sondern nur darauf mal nebenläufig verweisen - aber wie (zuverlässig)?
Soviel erstmal meinerseits. Fand die Idee beim ersten Lesen erstmal recht merkwürdig plus dem “macht das mal in Docker, aber bei Docker bin ich raus”
Aber mittlerweile sehe ich da echt viele positive Möglichkeiten, welche sich dadurch ergeben können (wenn man’s gut macht). Würde sowas wirklich stark begrüßen.
Ich hoffe ich hab jetzt hier niemanden erschlagen xD
Gruß,
asca
*) Ja mir ist bewusst, dass wenn man Altbestände mit erfassen möchte (was sinnvoll wohl wäre), dann halt vieles abfragen wird und dass man natürlich das nicht alles auf einmal rausballertan Anfragen an die Server und dort hohe Last erzeugt. Es geht selbstverständlich auch unter Berücksichtung dieser Umstände. Anfangen für ein Test würde ich sowieso erstmal nur z.B. dt. Forum im Zeitraum der letzten x Monate.