Adding on to this, since I can’t find anybody else who’s figured this out and posted it:
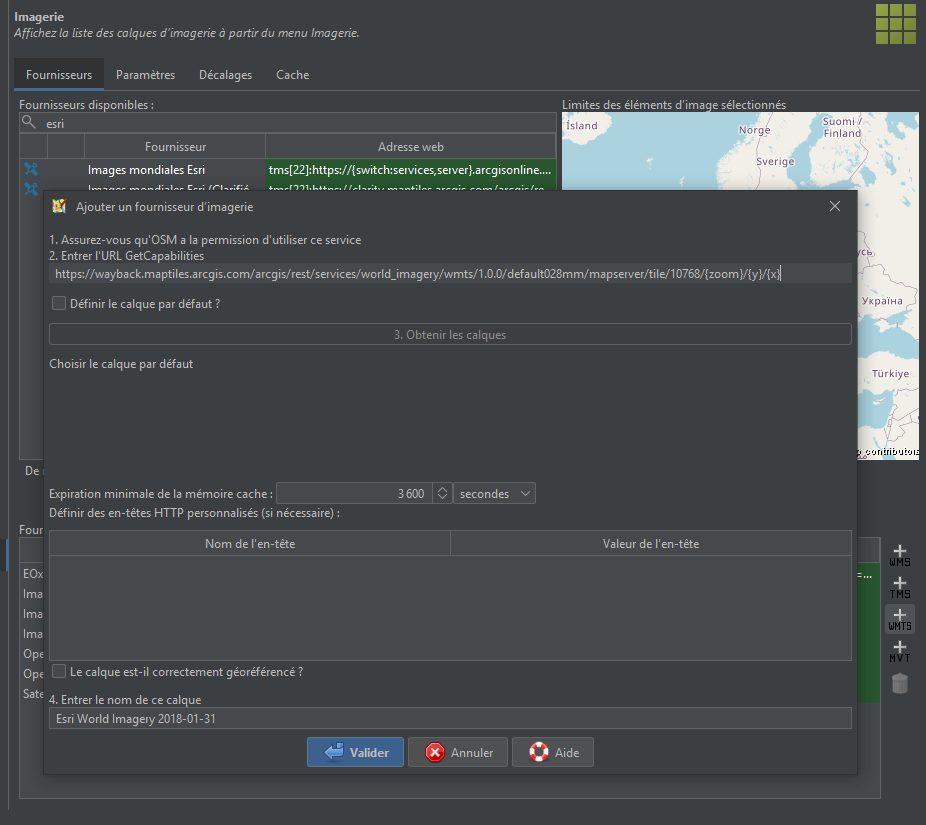
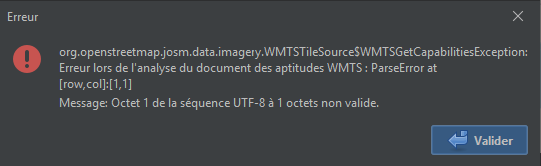
Esri World Imagery Wayback does have a WMTS capabilities endpoint exposed—but they broke the XML namespaces in the file by upgrading the URIs to HTTPS. Because of this, JOSM raises a cryptic error message about the endpoint having no layers when trying to add the imagery source (other editors that comply with the WMTS schema also do this). To fix this, you can
download the file;
modify your local copy by rewriting the root Capabilities element, substituting all instances of https with http in each URI;
import the modified capabilities document as an WMTS imagery source, using the URI file:///<PATH_TO_FILE>.
If you’ve succeeded, you should now be able to pull any available Wayback imagery without having to manually add each one as a TMS layer per Kensok’s diary entry on this. I would recommend selecting the layers with the matrix set identifier “default028mm”, since they have better quality imagery for whatever reason.
Someone should probably file a bug report with Esri for this; in the mean time, this is the least annoying solution. You can automate this with a script and cron job or task scheduler of your choice; I use this script
import re
import requests
WMTSCAPABILITIES_OUTPUT = r"D:\projects\osm\esri\wayback_WMTSCapabilities.xml"
ESRI_WAYBACK_WMTSCAPABILITIES = (
"https://wayback.maptiles.arcgis.com"
"/arcgis/rest/services/world_imagery/mapserver"
"/wmts/1.0.0/wmtscapabilities.xml"
)
XML_NAMESPACE_REGEX = re.compile(
r"(?:((?:xmlns|xsi)(?::\w+)?)=\"https?:\/\/([^\"]*?)\")+"
)
with requests.get(ESRI_WAYBACK_WMTSCAPABILITIES) as r:
if r.status_code != 200:
exit()
with open(WMTSCAPABILITIES_OUTPUT, "w") as f:
body = XML_NAMESPACE_REGEX.sub(r'\1="http://\2"', r.text)
f.write(body)